4 Consumer preferences, constraints and choice, demand functions
4.1 Consumer preferences, indifference curves/sets (0.5 weeks)
We will cover most of O-R chapter 4, but we will skip section 4.6 (differentiability)
4.1.1 “Bundles of goods” (O-R 4.1)
Let’s consider two goods only, for now.
In O-R notation:
The set of alternatives is \(X = \mathbb{R}_+^2\).
A member of X is called a ‘bundle’.
We can consider these bundles as ‘vectors’ (from linear algebra) with the corresponding operations. For example, let bundle \(x = (x_1, x_2)\). If \(\lambda\) is a positive number, we have \(\lambda x = (\lambda x_1, \lambda x_2)\).
We can depict these bundles graphically as vectors (or points) in 2-d space.
We will later consider ‘convex combinations’ of particular bundles x and y: \(\lambda x + (1- \lambda) y\), for \(0 \leq \lambda \leq 1\); all such convex combinations lie on the line segment connecting points x and y.
4.1.2 Preferences over bundles, indifference sets (indifference curves) (O-R 4.2 and supplements)
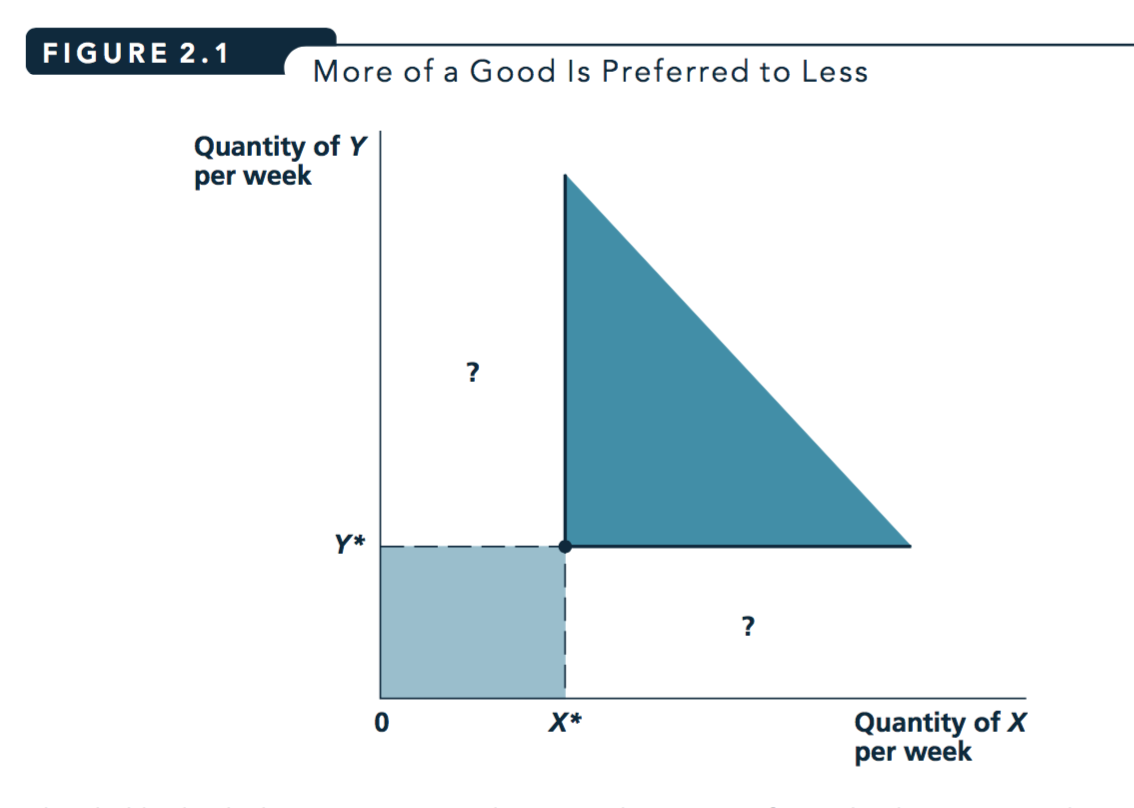
Figure 4.1: From Nicholson and Snyder 2010
If ‘more is preferred to less’, we know that all of the points in the darker region are preferred to all of the points in the lighter region. But how can we compare the “?” areas? Which are preferred? This will depend on how an individual weighs tradeoffs between X and Y.
\(\rightarrow\) We can depict this using Indifference Curves (indifference sets).
O-R:
The indifference set for the preference relation \(\succsim\) and bundle \(a\) is \(\{y ∈ X : y \sim a\}\)
Read this as ‘all y in the choice set X that are seen as equally good as bundle a’.
- Indifference curve (simpler definition, using utility)
- A curve that shows all the combinations of goods or services that provide the same level of utility. (Source: Nicholson and Snyder, 2010)
Formally (for 2 goods), the set of pairs of \({x,y}\) such that \(U(X,Y)=c\) for some constant c.
Autor:
Define a level of utility say \(U(x) = U\). Then, the indifference curve for U, \(IC(U)\) is the locus of consumption bundles that generate utility level U for utility function \(U(x)\).
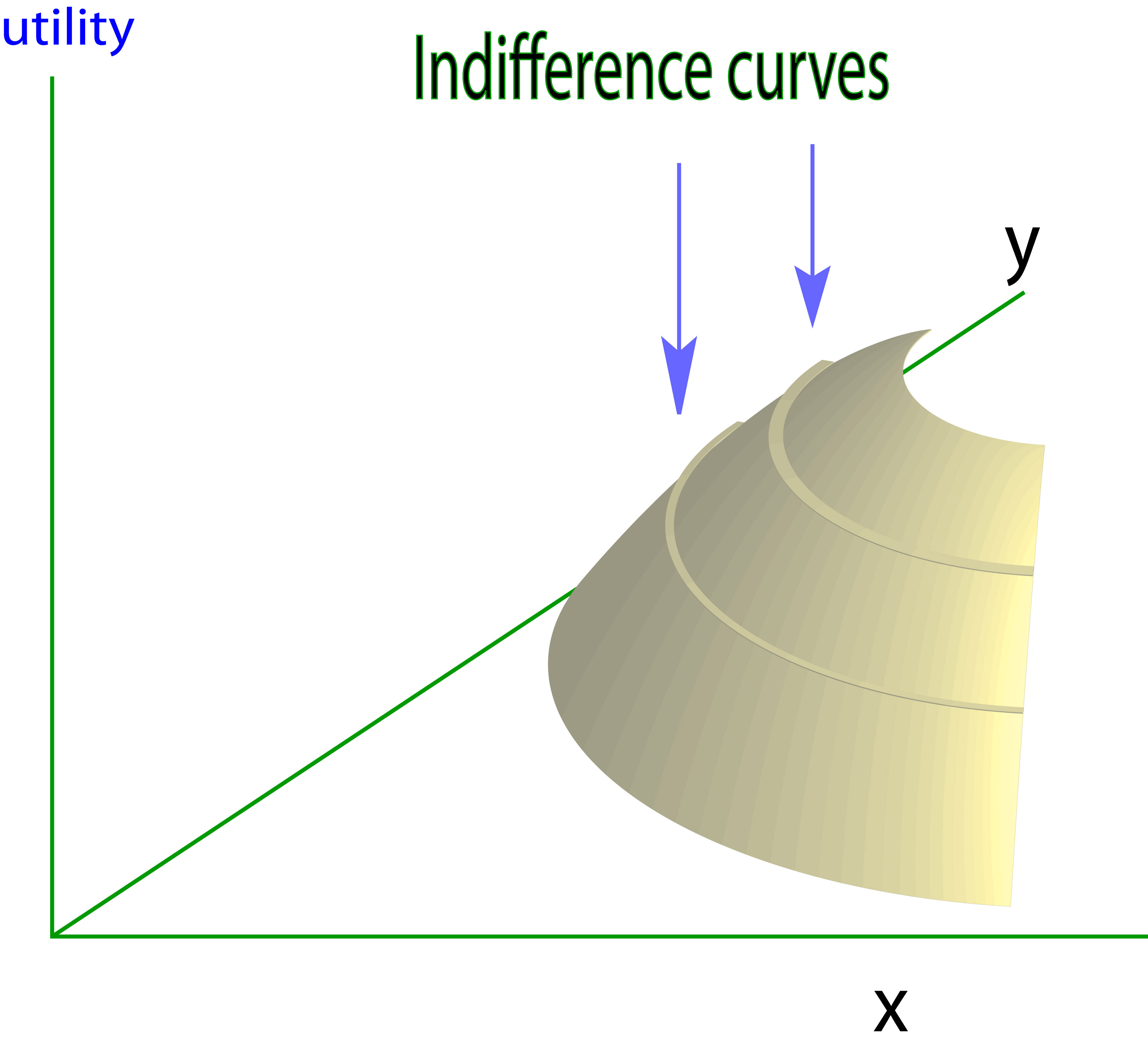
[Credit: www2.econ.iastate.edu].
Think of this as a map with a projection above it.
How far East you go on this map determines how much of the x good is consumed
How far North you go determines how much of the Y good is consumed.
How ‘high’ is the projected image… determines how much utility is obtained from this combination of goods X and Y.
Hmm… If we think of this as a traveler who loves ‘getting high’, and ‘consumes’ by riving East or North, and his utility is his altitude, maybe that helps.
This diagram is from a very useful resource from MIT, Frank’s Economics on the web.]
4.1.3 Examples of preferences (over 2 goods)
Simpler Definitions: Perfect substitutes and complements
- Perfect substitutes
Goods A and B are Perfect Substitutes when an individual’s utility is linear in these goods
when she is always willing to trade off A for B at a fixed rate (not necessarily 1 for 1!)
Formally, in O-R ‘Example 4.1: constant tradeoff’ (for two goods)
… \(v_i\) is the [numeric] value she assigns to a unit of good \(i\) [here, for \(i = 1,2\)]
[This preference relation] is defined by … \(x \succsim y\) if \(v_1 x_1 + v_2 x_2 ≥ v_1 y_1 + v_2 y_2\).
Obviously this \(\succsim\) is represented by the utility function \(u(x_1, x_2) = v_1 x_1 + v_2 x_2\).
- Perfect complements
Goods A and B are Perfect Complements when an individual only gains utility from (more) A if she also consumes a defined (additional) amount of B, and vice-versa
These goods are ‘enjoyed only in fixed proportions’. E.g., left and right shoes (1:1) bicycle frames and wheels (1:2) or, perhaps, baking powder and flour (1:40) for someone who only eats soda bread.
These are not the same as the ‘complements’ and ‘substitutes’ in demand functions which we may see later, referring to the impact of changing prices.
4.1.4 Properties: Monotonicity
Read O-R section 4.3.
Know how to define, test, and compare at least two ‘monotonicity-type’ assumptions, e.g., Monotonicity vs Strong Monotonicity; see O-R p. 49.
Know how monotonicity rules out ‘bliss points’
Indifference curve for a ‘bliss point’ preference
Note that what McDL refer to as ‘Isoquants’ is a general term for a ‘level set.’ Indifference curves are a ‘level set for utility’ (if we have a utility representation).
Monotonicity (essentially) yields ‘optimizing consumers spend all their wealth over the relevant lifetime’. It enables:
Easier computation of optimization problems (with an equality rather than an inequality constraint )
Easier and the ‘comparative statics’ of these optimization problems
The derivation of results from ‘adding up restriction’
Explain the examples in the O-R table:
How do we know that ‘constant tradeoff preferences’ exhibit monotononicity?
Explain/prove that ‘complementary goods’ do not exhibit strong monotonicity.
Prove that lexicographic preferences have strong monotonicity
4.1.5 Properties: continuity - discussed in a previous section
4.1.6 Properties: Convexity (skipping the proofs)
Read O-R section 4.5, skipping the proofs, if you like.
(weak) Convexity (O-R definition)
\(\succsim\) on \(\mathbf{R}^2_+\) is convex if \(a \succsim b \rightarrow \lambda a + (1 − \lambda)b \succsim b\) for all \(\lambda \in (0,1)\)
Strict Convexity of \(\succsim\) (O-R definition) …
if \(a \succsim b\) and \(a \neq b \rightarrow \lambda a + (1 − \lambda)b \succ b\) for all \(\lambda \in (0,1)\)
Simply, weak convexity implies that convex combinations of two distinct bundles, one at least as good as the other, is at least as good as the ‘weakly worse’ bundle.
Strict convexity implies that this convex combination is strictly preferred to the ‘weakly worse’ worse bundle.
Note that as \(\succsim\) also holds (in both directions) for two bundles where \(a \sim b\), weak (strict) convexity implies that a convex combination of such bundles will also be at least as good as (better than) either bundle.*
Reading tip: when we make an mathematical statement and put multiple things in parentheses, you can read this sentence either ‘reading everything in parentheses’ or ‘reading none of the parentheses’.
E.g., “In (New) York people should (not) drive on the left side of the road.”
An equivalent definition involving ‘upper contour sets’
(proved equivalent in O-R proposition 4.2):
\(\succsim\) convex if and only if for all \(x^ {\ast} \in X\) the set \(\{x \in X : x \succsim x^{\ast}\}\) … is convex.
In other words, it is the same as saying
‘the set of all bundles at least as good as some bundle’ … (which we call the ‘upper contour set’) is a convex set.seed(
A ‘convex set’ is a set that is ‘closed under convex combinations’, i.e., it contains all of its convex combinations. For any two elements in a convex set, the convex combination of these elements is in the set as well.*
A convex set is pretty easy to visualise for a set in 2 or 3 dimensional space … but much harder when we go to higher dimensions. Yet most of the proofs will indeed generalise to higher dimensions. Remember, when we are dealing with real-world products and bundles, we are dealing with many important dimensions. E.g., a box of cereal could be considered to be described by a vector (or list) of characteristics, including, sweetness, saltiness, crunch, calories, carbohydrates, etc…. all of which a consumer may care about
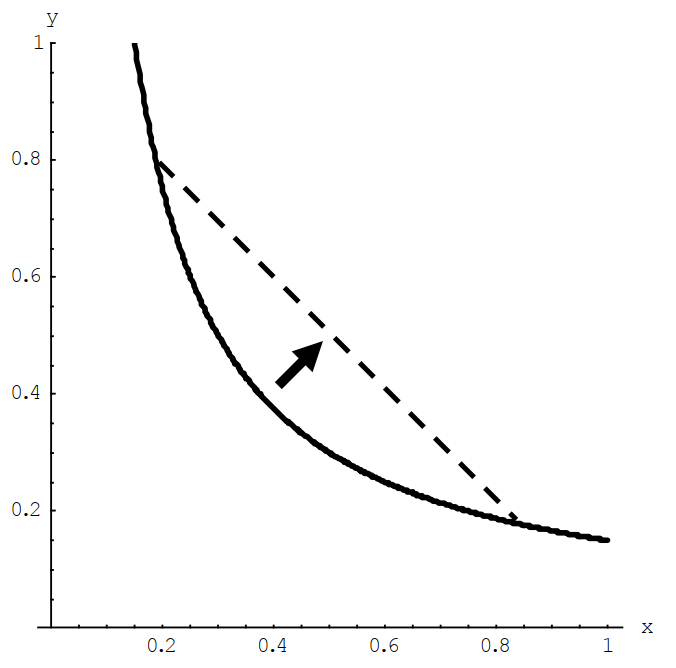
Figure 4.2: Convex preferences - from McDL
Be sure you understand the difference between the definition of convexity and strict convexity here.
Convexity:
A preference relation on \(R^2_+\) that is represented by a (quasi)-concave [utility] function is convex.
It will also have convex indifference curves, implying that the ‘weakly preffered to sets’ are convex.
Make sure you don’t get this confused.
See O-R proposition 4.3 and its proof.
The convexity of a strongly monotone preference relation is connected with the property known as decreasing marginal rate of substitution. (O-R)
Please see the O-R numerical/parametric example offering insight into this, beginning “consider three bundles.” If time permits I’ll make a quick video on this.
Convexity of preferences will ensure ‘well behaved consumer responses’, including demand responses to price (i.e., ‘demand curves’). Without convexity we may see abrupt and discontinuous shifts in the quantity of a good demanded in response to (small) changes in price.
Consider ‘substitute goods’ like
A. petrol (gasoline) versus B. diesel, or
A. scuba equipment versus B. skiing gear.
In these cases is easy to see why I may prefer ‘a lot of A or B’ over ‘a medium amount of A and B’, and my willingness to give up a good might decrease rather than increase as I have more of that good.
How to show (mathematically) that preferences (and indifference curves are convex)?
The answers here … by Abrink and Teytelboym appear correct. However, I do not want to get into this computational issue in this module. (However, it is covered in the ‘optimisation’ module).
More general concept: quasiconcavity (optional, linked as supplement)
This is the ‘preferred assumption’ which resembles convexity, but has several advantages as a concept. For example, it doesn’t require differentiable preferences, and its properties are not affected by monotonic transformations of utility functions. This is the concept that you might be taught in a PhD or MRes module. I think it may also have some value in understanding optimization problems in general, which is an important part of research and industry and finance, I believe. Linked as supplement here.
(Differentiability: mainly skip)
You can skip O-R’s discussion of differentiability.
However, do have a look at O-R figure 4.5 to get a sense of what differentiability means for indifference curves (indifference sets).
What do these indifference curves depict?
What might be a functional (utility) form consistent with these indifference curves?
Are these preferences ‘everywhere differentiable’? Explain why or why not.
Give a real-world example of a case where such preferences might be relevant.
4.1.7 Applications: Product positioning, marketing
Do people have a preference for balance? (Convex indifference curves)?
Naive argument?: If market research suggests that a broad group are indifferent between two options A and C, maybe they strictly prefer G \(\rightarrow\) a possible niche for a new profitable product?
But what may be a critique, exception to this logic, e.g., for a particular food?
Convex preferences, ‘preferring mixtures’ is a very strong assumption, unlikely to hold everywhere, or for actual mixtures. I may be indifferent between liver and custard, but it doesn’t mean that I prefer liver-flavoured custard, nor even necessarily equal amounts of liver and custard side by side.
Producing an ‘intermediate’ attribute may be more costly; it may be easy to make crunchy but low-taste cereal or tasty but low-crunch cereal, but expensive to make a cereal with both attributes.
E.g., it’s hard to make a car that is spacious and fast.
Utility/indifference curves: Also a framework for marketing analysis
The utility and indifference curve construct may seem highly theoretical. Indeed, these models were developed largely to address big questions like ‘who gains from trade?’ Still, it helps organise thinking and analysis for at least some managers and marketing groups. According to Nicholson and Snyder (2010) Marriot hotel used focus groups to ‘construct (multidimensional) indifference curves’ to consider their ideal product positioning.
I have seen a similar presentation for other hotels presented at Behavioural boozeonomics in London.
This may also provide a structure to guide data-driven ‘searches for the next best product’.
One (often survey-based) approach to this is called ‘conjoint analysis’ or ‘conjoint modeling’. Consider: How would the assumptions of this approach, as described below, translate into microeconomic assumptions about choices and preferences?
Note: the site provided by ‘Qresearch’, part of a commercial firm states things in loose terms, for those without Economics training.
[ ]](https://www.qresearchsoftware.com/conjoint-analysis-the-basics)
]](https://www.qresearchsoftware.com/conjoint-analysis-the-basics)
4.2 Consumer behavior/Individual (and market) demand functions and their properties (1 week)
Main reading:
- O-R Chapter 5 (selections as outlined below)
Feel free to skip (unfold):
You may skip the first part of O-R section 5.5 on ‘rationalizing a demand function.’
However, make sure you do read the discussion of ‘the weak axiom of revealed preferences’ (WARP). This relates to some of the supplementary readings/exercises.
Alternative treatments: (Unfold)
DA: Lecture Note 6 – Demand Functions: Income Effects, Substitution Effects, and Labor Supply, esp. sections 1-3
McDL: 3.1 (elasticity), parts of Ch 12; Warning: this book’s treatment of consumer surplus seems to be incorrect (or at least vastly oversimplified) from my PoV
QMC: Chapter 17 (elasticities – very clear treatment, Chapter 18 (supply and demand details)
Individual choices: supplementary recommended readings
As noted before:
You don’t need to read all of these
But you should read some of these… in terms of marking, you may need some themes to discuss in open answer questions on the midterm exam, for example.
Loomes, Graham, Chris Starmer, and Robert Sugden, 1991. “Observing Violations of Transitivity by Experimental Methods”. jstor link (Society 2014)
Choi, Syngjoo, et al. “Who is (more) rational?.” The American Economic Review 104.6 (2014): 1518-1550.a.
Waldfogel, Joel. “The deadweight loss of Christmas.” The American Economic Review 83.5 (1993): 1328-1336. (Waldfogel 1993)
Reinstein, David. “The Economics of the Gift.” (2014; working paper and chapter in Gift Giving and the’embedded’ Economy in the Ancient World, F Carlà, M Gori - 2014). (Reinstein 2014)
4.2.1 Choices are subject to constraints
You cannot spend more than your (lifetime) income or wealth \(\rightarrow\) budget constraints (and ‘budget sets’).
There are also other potential constraints on consumption, such as a leisure time constraint and legal constraints.
Consider the budget line given in figure 5.1 in O-R.
Budget constraint for two goods, slope \(-p_{x_1}/p_{x_2}\)
Only two goods? For example, think ‘food’ and ‘nonfood’.
Budget constraint algebra (simple)
*I realise this may be trivial for many of you, but others will find this a helpful refresher. If it is obvious, feel free to skip ahead.
I made a video with some simple algebra for budget constraints you can access here
If I spend all my wealth (which I should do over a ‘relevant lifetime’ given monotonic preferences), then, if there are only two goods \(x_1\) and \(x_2\) to choose from, with prices \(p_1\) and \(p_2\) respectively …:
Expenditure on \(x_1\) + Expenditure on \(x_2\) = wealth (\(w\))
\[p_1 x_1 + p_2 x_2 = w \]
To see how \(x_1\) trades off against \(x_2\), rearrange this to:
\[x_2 = \frac{w}{p_2} -\frac{p_1}{p_2}x_1\]
Intercept: \(\frac{w}{P_2}\), i.e., amount of \(x_2\) you can buy if you only buy \(x_2\)
Slope: \(-\frac{p_1}{p_2}\), i.e., how much \(x_2\) you must give up to get another unit of \(x_1\)
Notes and intuition (unfold if you want more explanation)
The slope \(-\frac{p_1}{p_2}\): How much \(x_2\) I must sacrifice to get another unit of \(x_1\), expressed as a negative number. (Strictly speaking, the slope is how much \(x_2\) you get when you get another \(x_1\), but since this is negative we see that you ‘get a negative amount’, i.e., give up some amount of \(x_2\).)
To get another unit of \(x_1\) it costs me \(p_1 x_1\), so the more costly is \(x_1\) the more \(x_2\) I must give up.
For each unit of \(x_2\) I give up I save \(p_2\), so the more costly is \(x_2\) the more I can save by giving up 1 unit of it, thus, the less I need to sacrifice of \(x_2\) to get another unit of \(x_1\).
O-R also refer to a different way of presenting the consumer’s environment:
Rather than assuming that the consumer can purchase the goods at given prices using his wealth, assume that he initially owns a bundle \(e\) and can exchange goods at the fixed rate of one unit of good 1 for \(\beta\) units of good 2.
This presentation helps us consider the welfare properties of exchange economies under different conditions and ‘initial allocations’. However, we will not be covering this here.
Budget sets (O-R 5.1, formal presentation); normalization
O-R definition (for two goods)
… the budget set of a consumer with wealth \(w\) when the prices are (\(p_1, p 2\)) is
\[B((p_1, p 2), w) = \{(x_1,x_2) \in X : p_1 x_1 + p_2 x_2 \leq w \}\]
(Note that the part after the colon (\(p_1 x_1 + p_2 x_2 \leq w\)) is referred to as the ‘budget constraint’)
The set \(\{(x_1,x_2) \in X : p_1 x_1 + p_2 x_2 = w \}\) is the consumer’s budget line
O-R continue:
Geometrically, a budget set is a triangle like the one in Figure 5.1. Note that multiplying wealth and prices by the same positive number does not change the set:
\(B((\lambda p_1,\lambda p_2), \lambda w) = B((p_1, p_2), w)\) for any \(\lambda > 0\),
because the inequalities \(\lambda p_1 x_1 + \lambda p_2 x_2 \leq \lambda w\) and \(p_1 x 1 + p_2 x_2 \leq w\) that define these sets are equivalent
Multiply all prices and income by the same amount, and the budget constraint is unchanged. This will imply that we can simplify any such maximization problem by “normalizing” the budget constraint so that one good simply has price equal to one. (But if this is an applied problem, we should remember to convert it back into the actual prices.) (See my ‘numeraire good’ video.)
Also: As the budget constraints are unchanged when all prices and wealth are increased by the same proportion, neither will be the choices made; thus demand functions must be “homogenous of degree zero”, as noted below.
“Every budget set is convex” (*)
As O-R show algebraically (for two goods, but this would extend to \(n\) goods)…
- if any two bundles \(a\) and \(b\) are both within a particular budget set, a third bundle that is a “convex combination” of these two bundles will also be in this budget set.
* This holds as a result of constant linear pricing; in the proof you see this is used. With complicated (e.g., nonlinear) pricing, or subsidies that only apply to certain units (recall ‘eat out to help out’?) budget constraints may not have this property. Perhaps it is reasonable to assume that a ‘standard small consumer’ faces constant prices for many goods. On the other hand, we can think of all sorts of exceptions, where you get a discount if you buy in bulk and also note that you cannot buy, e.g., “one third of a car.” With nonlinear budget constraints optimization problems become much more mathematically “interesting”.
What’s a “convex combination”? (unfold)
Essentially this is just a fancy economics word for “shares of two things adding to one”.
It is simply some (non-negative) share of the first bundle and one minus this share of the second bundle. E.g., 100% of the first bundle and none of the second bundle, or 50% of each bundle, or 25% of the first bundle and 75% of the second bundle. (Obviously this could be extended to to multiple bundles too.)
Think also about ‘dividing up two bundles’. We see that if there are two bundles out there and one person takes a convex combination of these that is convex, what remains is also a convex combination of these.
Formally the convex combinations of bundles \(A\) and \(B\) (where A and B are vectors) are simply \(\delta A + (1-\delta) B\), where \(0 \leq \delta \leq 1\). (This can be extended to convex combinations of several bundles to consider a ‘convex hull’, and each bundle can have as many elements as desired.)
Consider of any two bundles A and B, each with two elements, plotted on the coordinate plane. Any convex combination of A and B is a points on the straight line connecting A and B. Thus the line connecting A and B contains all such convex combinations. Each particular convex combination \(delta A + (1-\delta) B\) will be the point\(\delta\) share of the distances between A and B.
We could use this to demonstrate “gains to trade”. Suppose two people with the same preferences, each with a distinct bundle (at a point other than the one where their MRS are the same). They can divide up these bundles among each other, one taking a convex combination of the bundles, and the other taking the remainder, which is also a convex combination.
See THIS SUPPLEMENT for more detail.
4.2.2 Individual (consumer) demand functions (Marshallian demand) - first pass
O-R:
A demand function is a function \(x\) that assigns to each budget set one of its members.
Define \(x((p_1, p_2), w)\) to be the bundle assigned to the budget set \(B((p_1, p_2), w)\).
(It is easy to imagine extending this to a case with many goods to choose from, rather than just two.)
O-R note that if you multiply all prices and wealth by some positive constant \(\lambda\), the budget set is unchanged; thus the demand function is also unchanged.
As the demand function is (stated above to be) a function of the budget set, and nothing else, (at least holding preferences constant), if the ‘budget set as an argument’ is unchanged, the output must not change.
Considering \(x(p_1, p_2, w)\) as a simple function of three arguments, this implies it has the mathematical property ‘homogenous of degree zero’. A function is ‘homogenous of degree \(n\)’ when multiplying all of its inputs by some number \(\lambda\) causes the output to be multiplied by \(\lambda^{n}\). … Here, Hd-0, so \(\lambda^{0} = 1\) …. i.e., the output is unchanged.
O-R present ‘individual demand functions’ before presenting the optimisation problem. This is unusual… why do they do this?
They highlight that the demand function does not need to arise from an optimization process (as we describe below)… it merely maps from the budget set to a particular choice.
This can arise as a result of a simple rule or “heuristic” such as “spend equal amount of income on each good”. Behavioral economics considers the implications of decisions made on the basis of such heuristics.
Types of demand functions: Marshallian and Hicksian…
These demand functions are stated as a function of the budget set, or more simply, as functions of price and wealth (or income). These are referred to as the “Marshallian demand functions” after the great Alfred Marshall. These are the demand functions that we may actually be able to observe in the real world. Marshallian demands show the optimal amount of a good as a function of prices and income. I.e. \(x_1(p_1, p_2, m)\). The function tells us how demand for, say \(x_1\) responds to changes in price holding income fixed.
There are another type of demand functions that have very interesting properties for theory and welfare analysis called “Hicksian demand functions” or “compensated demand functions”. These take prices and utility as the arguments. We will not cover these in 2020 because of time constraints. But as an Economist you should have some familiarity with this.
4.2.3 Rational consumer and his/her optimisation problem
We started with an individual’s preferences, one of the base elements of the neoclassical model. Under some conditions these can be described by utility functions, which we may consider as ‘mountains’ with levels sets depicted by indifference curves.
So, we have a way of depicting what people prefer, but this doesn’t tell us what people will choose to consume (and firms to produce).
We next introduced the second fundamental element of the neoclassical model, constraints, in particular, the budget constraint.
We put these together to describe the consumer’s problem: maximizing her utility subject to her budget constraints. This is depicted in figure below for the two-good case.
(Or see O-R fig 5.3)
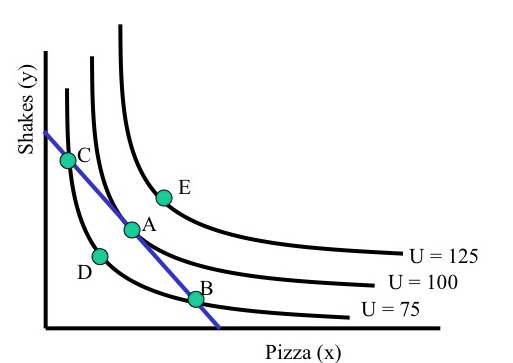
Imagine that you are this consumer with these preferences and this budget constraint. You can choose any point at or below the straight blue line, as it is on or below your budget constraint. You want to get to the highest indifference curve, to attain the most utility.*
* Again, this is material that you will have seen before if you have studied Economics. Feel free to skip this if you remember it all; the O-R text gives a concise explanation.
As this is a bit remedial I will not cover it in detail. I suggest the Khan academy videos/materials here if you need revision.
How do we know point B is suboptimal (i.e., not optimal)? What about point D? What about points between A and B? How do such points compare with point B?
We can see B is suboptimal as it is on a lower indifference curve than A, but both are on the same budget line. Same for D.
In fact, if we assumed even weak monotonicity we would already know that point A was preferred to point D.
Points between A and B are also below the ‘\(U=100\)’ indifference curve… again, with weak (or strict) monotonicity these must be inferior to point A (but superior to point B).
We can demonstrate that you will choose point A, yielding utility \(100\). What is special about point A?
It’s the point of tangency between the budget constraint and an indifference curve. It’s also (not a coincidence) the point where the slopes are equal. At this point (but not in general!) we have that “Slope of budget constraint = slope of indifference curve”.
4.2.4 Marginal rates of substitution
O-R section 5.4 ‘Differentiable preferences’
Note that O-R use the notation
\(v_1(z)\) and \(v_2(z)\) to represent “the consumer’s valuations of small changes in the amounts of the goods she consumes away from z”. They refer to the consumer’s ‘local valuations at z’ (remember that \(z\) is a bundle of goods).
This is usually referred to as the marginal utility; the partial derivative of the utility function with respect to each argument (each good or service), at a particular point (bundle), say \(z = (x_1, x_2)\):
\[mu_1(z) \equiv \frac{d}{d x_1} u(x_1, x_2)\]
O-R define the “marginal rate of substitution at \(z\) … \(MRS(z)\)” as \(v_1(z)/v_2(z)\)
Assume bundle \(z\) contains elements \(x_1\) and \(x_2\). Relating this to a more standard notation:
\[MRS(z) = MRS(x_1,x_2) = v_1(x_1,x_2)/v_2(x_1,x_2)=\frac{mu_1(x_1,x_2)}{mu_2(x_1, x_2)}\]
I prefer to define and think of the MRS as
Starting from a particular point (\(x_1', x_2'\)) how much \(x_2\) would I be willing to give up to get a unit of \(x_1\)‘? (As this ’unit size’ converges to 0, as we are considering a point slope here. )
Or starting from a particular point … if I gained a tiny tiny unit of \(x_1\) how much \(x_2\) would I have to give up to hold my utility constant?
I loosely derive the ‘ratio of the marginal utilities’ from this definition BELOW, offering some insight.
Above, at an optimal interior consumption choice, we had that the “slope of budget constraint = slope of indifference curve”… at least that’s what it looked like.
This is equivalent to “the point or bundle (which we will call \(x^{\ast}\)) where the price ratio equals the marginal rate of substitution”, i.e., the point \(x^{\ast} \equiv (x_1^{\ast},x_2^{\ast})\) where
\[p_1/p_2 = MRS(x^{\ast}) = MU_1(x^{\ast})/MU_2(x^{\ast}) =v_1(x^{\ast})/v_2(x^{\ast}) \] holds.
Warning: Recall that the marginal rate of substitution may vary everywhere along an indifference curve (remember the idea of satiation and diminishing MRS).
Unfold for further explanation…It is a function of the point it is evaluated, i.e., \(MRS = MRS(x_1, x_2)\). It is only at the point where the consumer is optimizing that these slopes must be equal.
They can also be equal at some other suboptimal points, where she is not spending all of her income… (e.g., perhaps point D in the above figure).
Where she is consuming some of every good, this is a necessary condition for such a point to represent an optimal consumption choice, but it may not be a sufficient condition. May also be optimal for her to consume none of certain goods, in which case this condition will not hold. We return to this later.
At an optimal ‘interior’ consumption choice (with strict convexity, see above note and discussion of ‘corners’ below)
Consume all of income (locate on budget line; follows from ‘more is better’)
The “Psychic tradeoff” (MRS) equals the market tradeoff (\(p_X/p_Y\))
Intuition: If I can give up X for Y in the market (buy less X, get more Y) at a certain rate, and the benefit I get from doing this is at a different rate, I can make myself better off.
Thus the original point could not have been optimal!

If this is not clear to you, try to think about this carefully. This is a key insight in microeconomics, a sort of ‘marginality’ argument/‘proof by contradiction’. that will come back later.
Very simple example, for intuition
Suppose that at the consumption bundle you choose, your MRS = 1. To remain indifferent, you would be willing to give up 1 hamburger to get 1 soda.
Suppose the price of soda is £1 and the price of a hamburger is £2. \(\rightarrow\) Price ratio: \(P_S/P_B = 1/2\)
Thus if you buy one less hamburger you can buy two more sodas. Thus if you give up one hamburger, you can get one more soda to keep you indifferent plus an additional soda. This means you would be better off; thus the original bundle wasn’t optimal.
Practice question: in which direction would you adjust this bundle if the price of a soda was £2 and a hamburger was £1?
More extended example… (unfold)
E.g., if I can give up one glass of wine and gain two beers (i.e., because wine is twice as costly), and (given my proposed consumption of wine and beer) I get the same value from each glass of wine or beer, I can give up this glass of wine, gain two beers, and make myself ‘one unit’ better off, at the margin.
On the other hand, if I can give up one glass of wine and gain two beers (i.e., because wine is twice as costly), and (given my proposed consumption of wine and beer) I get the four times as much value from each glass of wine as each beer, I can give up two beers, gain a wine (which I value at four beers) and make myself ‘two units’ better off, at the margin.
However, I can not apply this argument to a point where I am consuming only wine… I cannot consume less than no beer (although some nights I wish I could have done). We return to this point below
More insight into MRS
Recall \(u=u(x_1, x_2)\).
\[U_1(x_1,x_2) \equiv MU_{x_1}(x_1,x_2)\]
Derivative with respect to \(x_1\): rate that utility increases if we add a little \(x_1\), holding \(x_2\) constant.
Similarly for \(MU_{x_2}\).
As noted (and we can derive this), the MRS at a point is the ratio of these marginal utilities.
MRS: ‘how much \(x_2\) would I be willing to give up to get a unit of \(x_1\)’?
Ans: Depends on marginal benefit of each … we can show \(MRS(x_1,x_2)=\frac{MU_{x_1}}{MU_{x_2}}\)
Mathy intuition:
The more valuable a little more X is to me at that point – the higher is \(MU_{x_1}\) – the more \(x_2\) I am willing to give up to get it. That is why \(MU_{x_1}\) is in the numerator.
The more valuable a bit more \(x_2\) is at that point – the higher is \(MU_{x_2}\) – the less \(x_2\) I am willing to give up to get a bit more \(x_1\). That is why \(MU_{x_2}\) is in the denominator.
The ‘first order change in utility’ (or ‘total differential’), considering ’small changes in \(x_1\) and \(x_2\), \(d_{x_1}\) and \(d_{x_2}\) is:
\[ dU = \frac{\partial U}{\partial x_1}d_{x_1} + \frac{\partial U}{\partial x_2}d_{x_2}\] \[ = MU_{x_1}d_{x_1} + MU_{x_2}d_{x_2}\]
… Where \(\frac{\partial U}{\partial x_1}\) refers to the partial derivative of \(U(x_1,x_2)\) with respect to \(x_1\), and similarly for \(x_2\), i.e., the marginal utility.
Essentially, for very small changes in X and Y; this approximates the total change in utility. It’s a ‘linear projection’.
Setting it equal to 0 and rearranging yields the rate, at the margin, one is willing to give up \(x_2\) for \(x_1\):
\[dU = MU_{x_1}d_{x_1} + MU_{x_2}d_{x_2} = 0 \]
Rearranging…
\[\frac{dx_2}{dx_1}=-\frac{MU_{x_1}}{MU_{x_2}}\]
Tech note: This is a simple case of the implicit function theorem. Essentially \(U(x_1,x_2)=c\) defines an implicit function \(x_2(x_1)\), whose slope is the negative of the ratio of the derivatives.
Rearranging the utility maximising condition yields further intuition:
\[\frac{P_X}{P_Y} = MRS(z^*) = \frac{MU_X(z^*)}{MU_Y(z^*)}\]
(at each interior consumption point \(X>0\), \(Y>0\))
\[\frac{MU_X}{P_X} = \frac{MU_Y}{P_Y}.\]
I.e., the same ‘bang for each buck’.
Note: If this didn’t hold true and you were spending on both goods, you would be paying ‘more per util’ for one good than the other, and thus should reallocate to that other good.
4.2.5 Note on ‘corner solutions’
The above ‘bang for the buck’ condition applies to any interior solution
If you are consuming both goods and optimising, \(P_{x_1}/P_{x_2} = MRS = MU_{x_1}/MU_{x_2}\) must hold
This is a “necessary but not sufficient condition”, sufficient if there is a diminishing MRS everywhere.
But you might consume none of some good (say \(x_1\)):
If even with no \(x_1\) we still have \(MU_{x_1}/P_{x_1} <MU_{x_2}/P_{x_2}\)
- i.e., the marginal utility of the first unit of \(x_1\) is less than that of \(x_2\).
The same condition applies to each good you are consuming a positive amount of.

Figure 4.3: From Autor notes
4.2.6 Overview: Solution to consumer’s problem
General solution (two goods)
O-R (proposition 5.1) present the basic results for the solution to a consumer’s problem (at least for two goods):
[Consider] a preference relation on \(\mathbf{R}_+^2\) and a budget set
- If the preference relation is continuous then the consumer’s problem has a solution.
By this they mean, that ‘there is a highest point in this set’. They cite a ‘standard mathematical result’.
This seems obvious; at first glance you might think ‘every set must have a minimal and maximal element’.
But then, think about the set “numbers that are strictly below 10”. Is there a largest number in this set? (No, there isn’t.)
- If the preference relation is strictly convex then the consumer’s problem has at most one solution.
The proof of this is pretty neat!
First they ‘assume the negation of b holds’ … and look for a contradiction:
Assume that distinct bundles \(a\) and \(b\) are both solutions to a consumer’s problem.
Then the bundle \((a +b)/2\) is in the budget set (which is convex); by the strict convexity of the preference relation this bundle is strictly preferred to both \(a\) and \(b\).
So, ‘if there are two optimal distinct bundles, there must be an even better bundle.’ Thus, a contradiction… so the negation of b cannot hold… there cannot be two distinct optimal bundles.
- If the preference relation is monotone then any solution of the consumer’s problem is on the budget line
(This one seems pretty obvious, skip the proof)
4.2.6.1 Solution with monotone, convex, and differentiable preference relation (two goods)
O-R summarize this nicely, allowing for the possibility of corner solutions"
Assume that a consumer has a monotone, convex, and differentiable preference relation on \(\mathbf{R}_+^2\). If \(x^{\ast}\) is a solution of the consumer’s problem for \((p_1, p_2, w)\) then
- \(x_1^{\ast}> 0\) and \(x_2 > 0\) \(\rightarrow MRS(x^{\ast}) = p_1/p_2\)
- \(x_1^{\ast} = 0 \rightarrow MRS(x^{\ast}) \leq p_1/p_2\)
- \(x_2^{\ast} = 0 \rightarrow MRS(x^{\ast}) \geq p_1/p_2\)
Consider each case for a-c, depicting these graphically. (See, e.g., O-R example 5.8)
You may also be familiar with the Lagrangian approach to constrained optimization. The interior solution (ignoring the corner solutions, i.e., not presenting the Kuhn-Tucker Lagrangian) is very quickly derived from the Lagrangian formula here, by Professor Joon Song
4.2.7 Some ‘popular’ forms for utility functions, and their properties; computation
Cobb-Douglas general form
\[U(X,Y)=X^aY^b\]
where a, b are positive constants
This is “homothetic” … what does this mean? (unfold)
Homothetic: MRS constant along a ray through the origin.
\(\rightarrow\) It can be represented by an HD1 utility function. This ties down ‘income effects’ in a boring way: consumption of each good expands proportionally in income.
…So the poor man just buys a tiny amount of foies gras and jumps in his tiny money bin.

Thus if everyone has these preferences th impact of one consumer’s income increasing by £1 million is the same as 1 million consumers gaining £1. This (possibly dubious) assumption underlies ‘representative consumer’ models.
A more formal and complete explanation of Homothetic preferences:
\[MU_X=\frac{\partial U}{\partial X} = aX^{a-1}Y^b\] \[MU_Y=\frac{\partial U}{\partial Y} = bX^{a}Y^b-1\]
Taking the ratio of these yields
\[MRS = \frac{a}{b}\frac{Y}{X}\]
So only the ratio Y/X affects the MRS; double both, MRS is the same.
Another relevant example: ‘Constant Elasticity of Substitution preferences’.
A non-homothetic (here, ‘Quasilinear’) example
\[U(X,Y)=X+ln(Y)\]
Here \(Y\) has a diminishing MU, but for \(X\) MU is constant
\[\frac{MU_X}{MU_Y}= \frac{1}{1/Y}=Y\]
So the MRS diminishes as \(Y\) decreases (as we go ‘down the indifference curve’ … this is what we confusingly call diminishing MRS), but it is independent of the amount of \(X\) consumed.
So, if we double both then what happens?
Ans: MRS doubles
This represents Quasilinear preferences:

These are particularly relevant with three or more goods.
More generally, quasilinear utility satisfies \(U=x_1+f(x_2,...,x_n)\); i.e., it is linear in one ‘numeraire’ good \(x_1\).*
* I discuss a numeraire price in this video.
Here, the amount of the ‘non-numeraire goods’ consumed adjust to match the price ratio but don’t depend on the income.
We imagine that ‘the tradeoff between these goods is the same for people of all income levels’.
E.g., in principal-agent analysis we can then ignore the question ‘but won’t the preference for leisure change when people are richer’?
Mathy intuition: if the ‘Y’ goods \((x2,..., xn)\) have more MU consume them ‘first’, until their MU diminishes to that of the numeraire, then consume X.
4.2.8 Rationalizing a demand function (Skip O-R section 5.5) {#}
We already considered ‘rationalizability of a choice function’ … so I won’t cover this special case.
4.2.9 (Weak axiom of) Revealed Preference
This comes largely from pages 67-68 of O-R.
Consider: Suppose a consumer is rational (chooses to maximise according to her preferences) and she has a monotone preference relation.
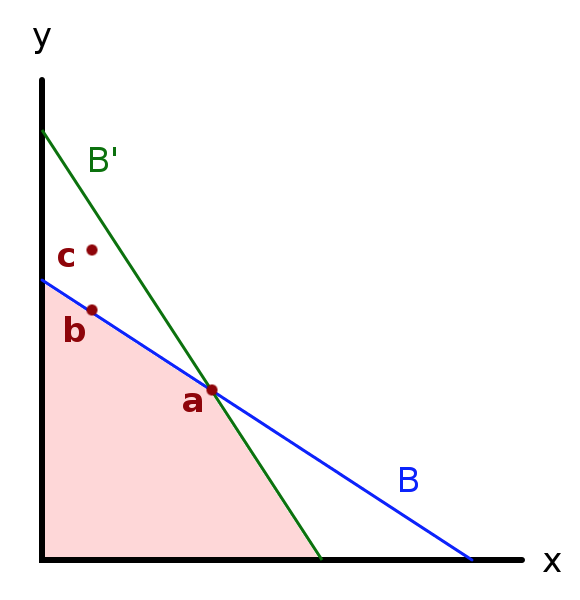
Consider the budget sets depicted above:2
- All points on or below the blue line … budget set \(B\)
- All points on or below the green line … budget set \(B'\)
Is it possible that she would choose bundle \(b\) in the (blue) budget set \(B\), and that this same person choose bundle \(a\) when faced with the (green) budget set \(B'\)?
Would this contradict rationality and monotonicity?
Indeed it would violate one or both of these.
It would violate what we define as the ’Weak Axiom of Revealed Preferences, as discussed below.
The main point
Note that both \(b\) and \(a\) were available in the (blue) budget set \(B\). If she chose \(b\) here, if she is optimizing, she must find it to be ‘at least as good as \(a\)’ … \(b \succsim a\), according to her preferences. We will say that such a choice implies ‘\(b\) is revealed directly weakly preferred to \(a\), or’\(b R^{D} a\)‘. (O-R say ’revealed at least as good’).
The \(R^{D}\) and \(P^{D}\) notation comes from Varian 1992; it is not used in O-R. Note that Varian seems to define the WARP differently, saying that it rules out that both \(A R^{D} B\) and \(B R^{D} A\) when \(A\) and \(B\) are distinct bundles. I will stick with the definition from O-R (also consistent with the current Wikipedia entry.)
Now note that in the (green) budget set \(B'\), both \(b\) and \(a\) are again available. In fact now, we note that in the green budget set ‘bundles with more of both goods than b’ are available.
So if she now chooses \(a\) this tells us that she prefers \(a\) to points with more of both goods than \(b\)’!
As O-R note:
For example, if an individual purchases the bundle (2,0) when she could have purchased the bundle (0,2), then we conclude that she finds (2,0) at least as good as the bundle (0,2) and prefers (2,0) to (0,1.9)
Given monotonicity, this implies that she must strictly prefer \(a\) to \(b\), i.e., \(b \succ a\). We say that such a choice implies ’\(a\) is revealed strictly preferred to \(b\).
Obviously, we cannot have that both \(b \succsim a\) and \(b \succ a\). Thus, either she is not choosing rationally, or she is indifferent between \(a\) and \(b\) and her preferences are not monotonic.
Consider…
Most students choose not to go on-camera in synchronous sessions: Should this be interpreted as revealed preference for online over face to face instruction? (Or at least for some aspects of it?)
Some videos on this:
First consider ‘mapping indifference curves’:
WARP: This is one of the few videos on Youtube that states it correctly. But it’s too slow. Watch it in 2x speed.
From O-R:
First they define ‘revealed preferred’ and ‘Revealed to be better than’
‘Revealed at least as good’
Given the demand function \(x\), the bundle \(a\) is revealed to be at least as good as the bundle \(b\) if for some prices \((p_1, p_2)\) and wealth \(w\) the budget set \(B((p_1, p_2), w)\) contains both \(a\) and \(b\) , and \(x((p_1, p_2), w) = a\) .
‘Revealed to be better than’
The bundle \(a\) is revealed to be better than b if for some prices (p_1, p_2) and wealth \(w\) the budget set \(B((p_1, p_2), w)\) contains both \(a\) and \(b\) , \(p_1 b_1 + p_2 b_2 < w\), and \(x((p_1, p_2), w) = a\) .
Next, the WARP is stated simply:
A demand function satisfies the weak axiom of revealed preference (WARP) if for no bundles a and b, both a is revealed to be at least as good as b and b is revealed to be better than a .
Finally, they state and prove that this is a necessary condition for a demand function of a rational consumer (with monotonicity):
A demand function that is rationalized by a monotone preference relation satisfies the weak axiom of revealed preference.
The proof of this is fairly simple (not covered here because of time and space concerns).
We can extend the WARP to ‘chains’ of revealed preference, so called ‘indirect revealed preferences’ This allows us to use sequences of choices to sketch out indifference curves for actual consumers.
There are also interesting ways to measure the ‘extent’ of violations of the revealed preference axioms. See:
Loomes, Graham, Chris Starmer, and Robert Sugden. “Observing violations of transitivity by experimental methods.” Econometrica: Journal of the Econometric Society (1991): 425-439.
Choi, Syngjoo, et al. “Who is (more) rational?.” The American Economic Review 104.6 (2014): 1518-1550.
4.3 Properties of (Marshallian) demand functions
This material is presented at a less advanced level than the previous material. I imagine for many of you, this will be revision, and feel free to skim it or skip it. More advanced material is considered further below.
Previously, we considered how consumption choices determined by utility functions/indifference curves and budget constraints. We can now consider how an individual’s choice of a good varies with each element of her budget constraint: for income and the price of each good.
The notation has changed here, to some extent.
We will refer to her ‘quantity demanded of good X’ function (or more simply, her ‘demand function’) as follows:
\[Quantity \: of \: X \: demanded = d_x(P_X, P_Y, I; preferences)\]
Homogeneity
- Homogenous (of degree zero) (demand) function
- A function whose outcome value does not change when all arguments are changed proportionally is homogenous of degree zero
\(d_X(P_X,P_Y,I)\) is homogenous of degree zero in its arguments.
Multiply all prices and income by the same amount, and the budget constraint is unchanged. Thus (as preferences have not changed) consumption choices should not change either.
- E.g., the budget constraint \(P_X X + P_Y Y = I\) is the same as the budget constraint \(2P_X X + 2P_Y Y = 2I\)
This relates to the puzzle of ‘why should monetary policy and inflation have any real effect on the economy?’
I discuss this in the context of a ‘numeraire price’ below:
4.3.1 Response to income changes
Q: What happens to the quantity purchased of some good as an individual’s income increases?
A: It depends on the preferences (i.e, the utility function, i.e., the relative curvature of the indifference curve at various points).
This defines whether the good is “normal” or “inferior.”
Whether it is normal or inferior depends on your preferences and the change in the slope of the indifference curves with higher income/utility, as we see below.)
Defining a normal and inferior good
- Normal good
- A good that is bought in greater quantities as income increases.
- Inferior good
- A good that is bought in smaller quantities as income increases.
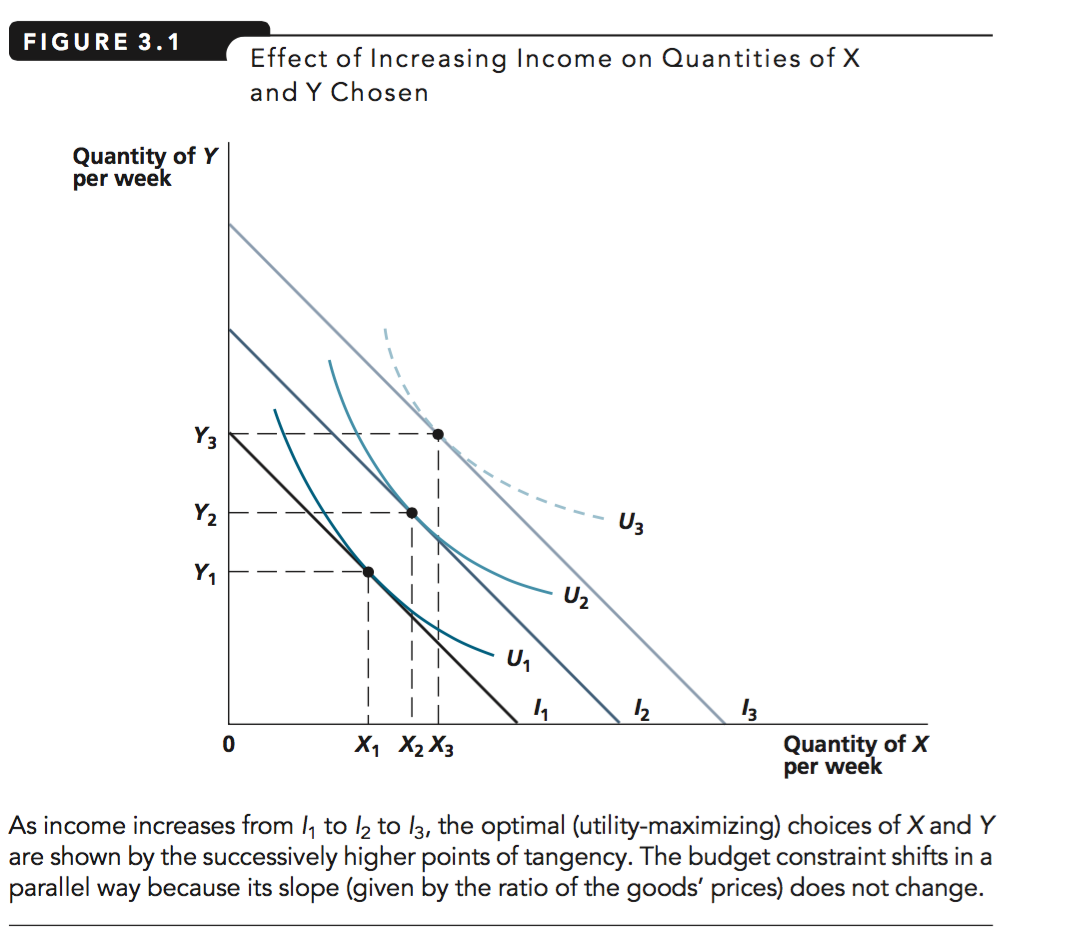
For a simple powerpoint supplement on this, see here
(download and use ‘presentation mode’)
Consider: Here we see more income \(\rightarrow\) less expenditure on Z! (Not just ‘a lesser share’ but actually less.)
This is because the shape of the indifference curves changes at higher incomes in this example. When people have a lot to spend, they want to spend it on Y and not on Z. (Again in this example, not in general.)
Consider, if you won the lottery how much pot noodle would you buy? Pot noodle may be like good Z in this example.
Thinking in 3d: ‘as you walk up this hill, its ridge gradually moves to the west’.
To be precise, this is not about wealthy people being different than poor people nor that their taste ‘changes’ when they become wealthy.
We are considering the same person with higher income, and thus the potential to choose a different bundle of goods.
Empirically, these are hard to distinguish, however.
There are ‘adding up’ conditions.
You always spend all of your income. Thus, if as your income increases, you spend less on some subset of goods, you must spend more on the remaining goods.
4.3.2 Response to (own) price changes (limited coverage)
What happens to an individual’s demand for a good as the price of this good rises, in our model? (I.e., if people are optimizing and their preferences obey all of the above axioms.)
You might have thought that when price rises quantity demanded falls, and vice versa, the so-called “iron law of demand”.
However, we cannot derive this from our model and in fact, when price rises, an optimizing consumer might demand more of this good or less of this good, we do not know!
If the good is inferior (as defined above) there will be two countervailing effects:
“Substitution effect”: Is a good (say, good ‘X’, on the X-axis) becomes more expensive, the budget line rotates (inward), and the point of tangency (where the price ratio equals the marginal rate of substitution) on any indifference curve moves towards a point with less of good X. In other words, ‘along a particular indifference curve’ the individual “substitutes away” from X as it becomes more expensive.
“Income effect”: As X becomes more expensive, the individual’s budget set is restricted. The individual is “poorer in a sense”. If X is an inferior good (in this region), this consumer, being ‘poorer’ chooses consume more of the good, all else equal.
If the second effect outweighs the first we have the surprising result that , and we label such a good a “Giffen good”.
To cover this in more detail, we would need to define another concept called “Hicksian demand” (see supplement).
4.3.3 Complements/substitutes; response to (other) price changes (limited coverage)
4.4 Consumer surplus (brief and incomplete treatment)
- Consumer surplus (Undergraduate definition: Nicholson and Snyder)
- The extra value individuals receive from consuming a good over what they pay for it.
- What people would be willing to pay for the right to consume a good at its current price rather than not being able to buy it at all.*
The area between the demand curve and the market price
A measure of consumer welfare, useful for policy analysis (unfold for some policy applications)
Policy, e.g.,
Impact of a tax or subsidy
Impact of allowing firms to merge
Impact of allowing a new form of price discrimination via (e.g.) ‘internet cookies’
This concept can also be applied to measuring the value added by the introduction of a new good. This is useful to know for policy, particular in formulating subsidies for R&D and in adjusting the CPI. It also could be used to compute damages in court cases where a firm is accused of stifling innovation.
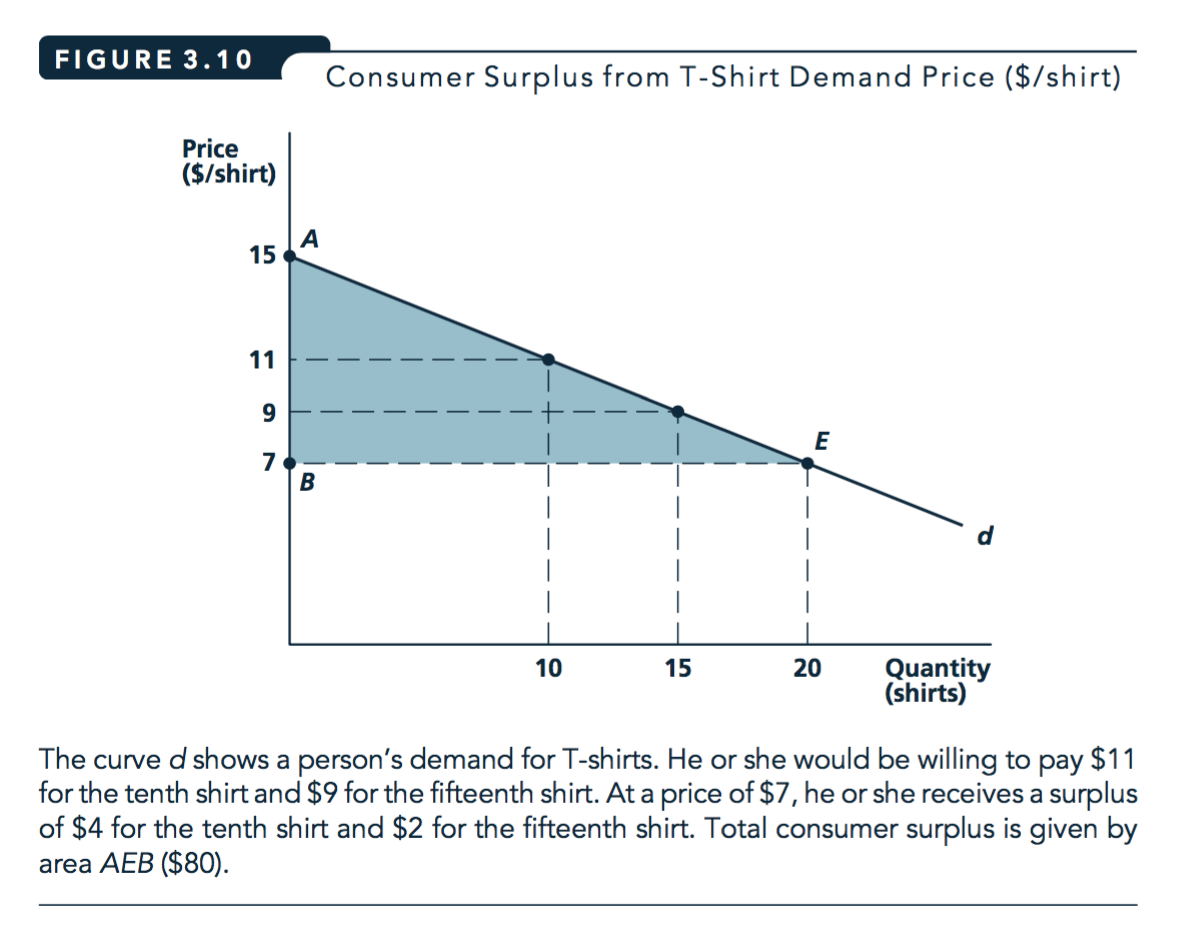
Figure 4.4: Source: Nicholson and Snyder, 2010
Also… This can be applied to the individual or market demand curve to obtain individual or total consumer surplus (although there are some technical issues with the latter).
Warning: The above is not precisely correct, it is an ‘undergraduate simplification’. This measure of of consumer surplus is not a great measure of welfare changes in response to changes in prices (or taxes). Some issues in the fold below.
Other measures of changes in consumer welfare include ‘equivalent variation’ and ‘compensating variation’ (neither of which we will have time to cover in 2020).
- Income effects: If we are using an individual demand curve … The consumer’s Marshallian (‘regular’) demand response as the price changes reflects both income and substitution effects.
To determine either:
the amount a consumer would be willing to pay to avoid a price change’, equivalent variation, or
‘the amount a consumer would need to be compensated to be no worse off after a price change’, the compensating variation
… we would need to know her ‘Hicksian’ or ‘utility-compensated’ demand curve; this is difficult or impossible to estimate.
- Aggregation: To get consumer surplus we want to sum the value each consumer gets from each unit. Suppose, as we derive/assume under perfect competition, firms are pricing at the marginal cost of the final unit produced. Assume that cost varies over time, so we observe shifts in the supply curve, tracing out points on the demand curve. This allows us to estimate a market demand curve. But this demand curve (inverted) only tells us the last consumer’s value of (willingness-to pay for) the final unit produced. We don’t know how other consumers valued each of these units.
With a linear demand curve this is a triangle, which has an area that is easy to compute. More generally, this is a ‘definite integral’.
\[\int_{0}^{q^\ast}p(q)-p^\ast dq \]
(where \(p(q)\) is the inverse demand).
For welfare calculations, we often want to know ‘how does this integral change as we adjust some parameter’?
\(\rightarrow\) See the (more general version of) the Leibniz rule for differentiating integrals., related to the ‘Fundamental theorem of calculus’.
4.5 Market demand (function) (brief and incomplete treatment)
- Market demand (or better, ‘market quantity demanded’)
- The total quantity of a good or service demanded by all potential buyers
This just sums the individual quantities demanded (at a given price)
- Market demand curve
- Relationship between total quantity demanded of a good and its price, ceteris paribus
- Sum the individual demand curves (‘horizontally’ … quantities demanded at each price)
Image source: McAfee et al, Introduction to Economic Analysis v. 2.1, chapter 2.3
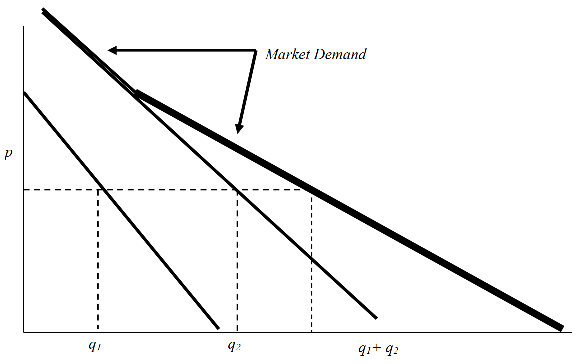
Figure 4.5: McAfee et al: Individual demand aggregates to market demand
Some of our previous results about individual demand also hold for market demand, while others do not, or only if we make restrictive assumptions.
Shifts in the market demand curve are caused by similar things that cause individual demand curve shifts
- Increases in overall income (for normal goods)
- Reduced prices of complements, increased price of substitute goods
- Change in tastes
However, the aggregate income does not have a single effect; it cannot be easily reduced to a single variable here. You can only express the demand curve as a function of aggregate income under restrictive assumptions. In general, it depends who gets this income. (See ‘aggregation issues’).
(In addition, the market demand curve could shift out if more consumers enter the market, e.g., because of demographic change.)
A random example:
4.6 Elasticities
This is a fundamental mathematics concept that comes from Physics; it’s not just for Economics.
- the change in quantity demanded of oranges when the price of oranges rises or
- the change in quantity demanded of apple juice when the price of apple juice rises?
(Or the response to changes in the price of a related good, or to income.)
Difficulty: These things are measured in different units and the prices have different starting values.
Elasticity: the measure of the % change in one variable brought about by a 1% change in another variable.
- a unitless measure; will be the same no matter how these variables are measured.
Think of responsiveness when talking about elasticity. Actually it’s a measure from physics having to do with rubber bands, they tell me.
Strictly speaking we are talking about the limit of these responses, i.e., derivatives.
The elasticity is basically the derivative of \(ln(y)\) with respect to \(ln(x)\); useful to know if you want to run a regression computing an elasticity, or if you want to interpret such a regression.
Actually, this, and its subtleties and interpretations is one of the most important things to comprehend for empirical work!!
- If a 5% fall in the price of oranges typically results in a 10% increase in quantity bought,
- we say that each percent fall in the price of oranges leads to an increase in sales of about 2 percent.
- I.e., the ‘‘elasticity’’ of orange sales with respect to price is about 2,
Note that elasticities may not be constant; they may depend on the starting point; e.g., linear demand implies a different price elasticity at each point.
Elasticities more precisely
calculate in terms of derivatives
estimated using log transformations*
(There is a decent video explaining how to interpret these regressions here, and another one here but you need to recall what is meant by ‘total differentiation’.)
* But see Santos-Silva’s 2006 warning about this.
4.6.1 Price elasticity of demand
Price elasticity of demand:
\[e_{Q_d,p} = \frac{percent \ change \ in \ Q_d}{percent \ change \ in \ p} \] \[ = \frac{\Delta Q_d}{Q_d}/\frac{\Delta p}{p}\]
This should always be negative (except for Giffen goods).
It is a unitless measure related to the slope of the demand curve.
It is very important for price-setting firms (more on this later).
From Nicholson and Snyder, 2010 (footnote):
If demand happens to take the ‘constant elasticity’ form \(Q = ap^b\) where \(b<0\), the price elasticity of demand is \(b\).
The constant-elasticity form is derived from the ‘constant elasticity’ using the method of ‘ordinary differential equations’.
This elasticity is the same everywhere along such a demand curve.
Taking logarithms of this yields \(ln(q) = ln(a) + b ln(p)\)
note that elasticities are often estimated by regressing logs on logs
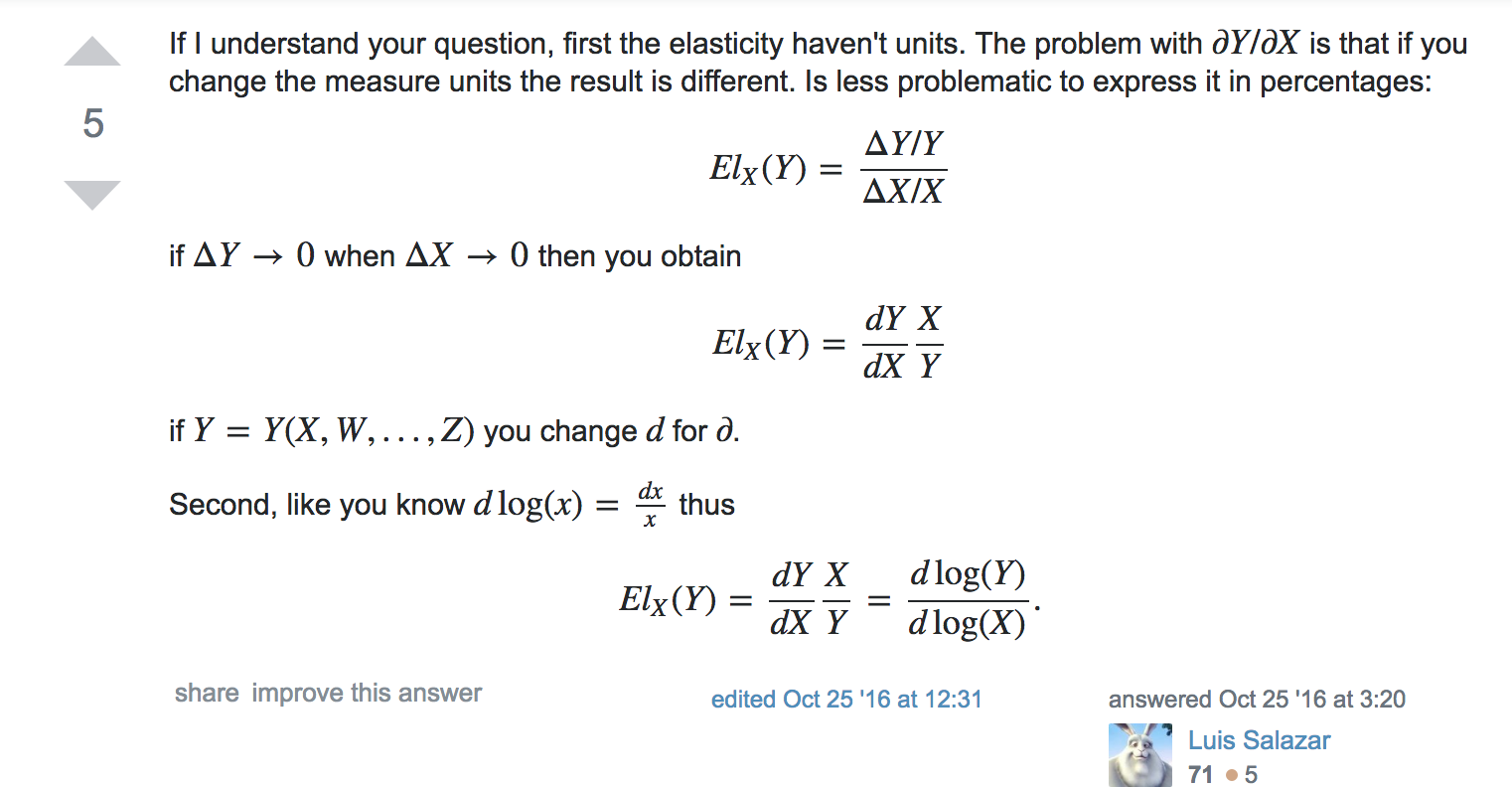
However
Indeed, one important implication of Jensen’s inequality is that the standard practice of interpreting the parameters of log-linearized models estimated by ordinary least squares (OLS) as elasticities can be highly misleading in the presence of heteroskedasticity.
- Santos-Silva and Tenreyro, 2006, ‘the Log of Gravity’.
Examples from the headlines
India’s Hike Messenger takes aim at WhatsApp
“Reliance ended up showing that there is elasticity in the market. If you drop prices, people will come on board,” he said.
‘Next’ to add more space despite retail sales ‘moving backwards’
The retailer does not expect any impact from the drop in sterling since the Brexit vote to kick in until at least the Spring of 2017, as it had hedged some of its foreign-currency exposures in advance. Still, it expects expenses to rise by up to 5 per cent next year.
‘The last time we had to increase prices (which was in 2010 when cotton prices soared) we estimated that price elasticity was around 1.1. If that remains the case today, a retail selling price increase of 5% would result in a fall in unit sales of -5.5% and a fall in like for like sales value of between -0.5% to -1.0%. In the scheme of things, we think that this drag on sales is manageable and less damaging than taking a significant hit to margin.’
4.6.2 Properties of price elasticity of demand
- Goods with many close substitutes at a similar price will be highly elastic
- with few substitutes … inelastic
- Typically: more elastic in the long run than the short run. Q : why?
We refer to price elasticities with the following terminology:
| \(e_{Q,p}\) | \(abs(e_{Q,p})\) | Term |
|---|---|---|
| \(< -1\) | \(>1\) | Elastic |
| \(= -1\) | \(=1\) | Unit Elastic |
| \(> -1\) | \(<1\) | Inelastic |
Note that sometimes elasticities are expressed in absolute value terms (a positive number). It should be clear from the context.
Consider an individual’s expenditure on a product.
The total expenditure (which will equal the firms’ revenue from this): price \(\times\) quantity = Expenditure (\(E\))
By taking the total differential of this and recalling the ‘multiplication rule’ of derivatives…
\[E = p(q)q = pq(p)\] \[dE = pq'(p)dp+q(p)dp\] \[dE/E = \frac{pq'(p)dp}{pq} +\frac{q(p)dp}{pq}\] \[dE/E = \frac{q'(p)dp}{q} +\frac{dp}{p}\]
We have that for small changes in price, the percent change in total expenditure is:
percent change in price + percent change in quantity
As \(e_{Q,P}\) tells you the percent change in quantity for each (small) percentage change in price, we can use this to determine the change in expenditure for a small change in price.
Considering very small increases in a good’s price:
If the (individual’s) demand is price-elastic, quantity will decrease by a larger percentage than price increased. Thus her expenditure (on this good) will decline.
If the (individual’s) demand is price-inelastic, quantity will decrease by a smaller percentage than price increased. Thus her expenditure (on this good) will increase .
If the (individual’s) demand is unit-elastic (with respect to price), quantity will decrease by a the same percentage as price increased. Thus her expenditure (on this good) will be unchanged.
Example and algebra…
If price rises by 20% and quantity demanded falls by 20% what happens to revenue?
Suppose \(p=10\) and \(q=10\) so \(TR=100\). Then when p=12 and q=8 TR=96. Huh? Price increased by 20% and quantity decreased by 20% so shouldn’t TR be unchanged? No! This only works for small changes.
TR is unchanged when \(p \times q\) stays the same. With a change in each \(\delta p\) and \(\delta q\), the new revenue is
\((p+\delta p)(q+\delta q) = pq+\delta p q + \delta q p + \delta p \delta q\).
This is the same as before if \(pq=pq+\delta p q + \delta q p + \delta p \delta q\), i.e., if
\(\delta p q + \delta q p + \delta p \delta q=0\), i.e., if
\(\delta p q + \delta p \delta q =-\delta q p\), i.e., if
\(\delta p q/p + \delta p \delta q/p =-\delta q\), i.e., if
\(\delta p/ \delta q (q/p) + \delta p /p =-1\), i.e., if
\(-e_p + \delta p /p = -1\)
In the limit, as \(\delta p\) goes to zero, this gives us that ‘unit elasticity means a small change in quantity leads to no change in revenue.’
Important question/result
Q: Suppose a firm is setting its price and selling to only one individual , and facing no competitors. It should basically never want to set its price at a point where demand is inelastic. Why not?
Ans: If it were at such a point, it could raise its price and its revenue would increase and costs would decline (because it would be selling fewer products but for greater total revenue.)
If I want to get to the highest point on a mountain, do I locate at a point with an ‘upward slope’?
I.e., do I choose a point where “if I move in some direction, I go higher”?
This is a key point, but also a common point of confusion. The point is the principle of (what I will call) ‘no room for improvement’. If I am at an optimal point I can do no better. Thus if I can do better, I must not be at an optimal point.
If the firm can increase its profits by increasing its price relative to its current price, then its current price is not profit-maximising.
A caveat is that it might do this for a long term strategic advantage; e.g., to gain customer loyalty and market share, intending to take its profits later. We come back to a related point later in the context of monopoly pricing.
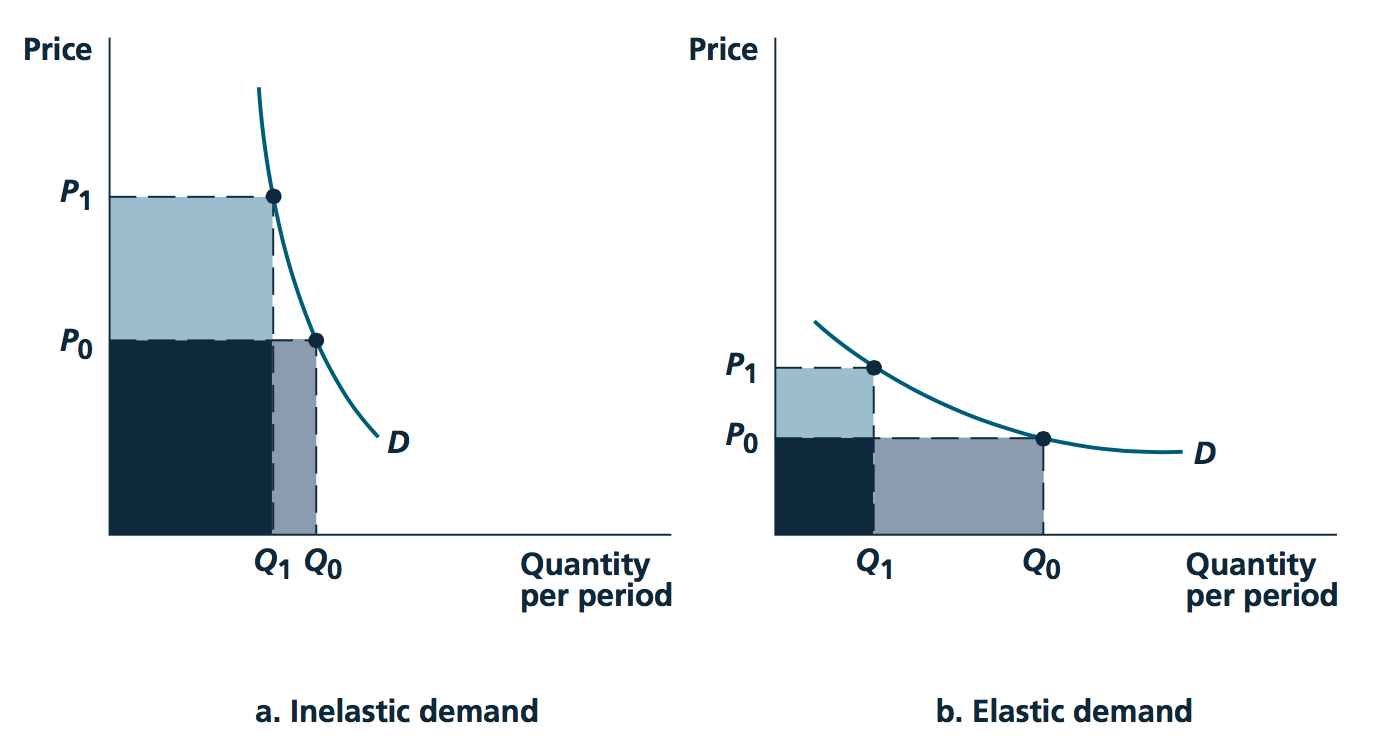
Image source: Nicholson and Snyder, 2010
4.7 Income elasticity of demand; Normal, luxury, and inferior goods
This video offers a good explanation of neccesity and luxury goods, and how this concept relates to inferior and normal goods.
- Income elasticity of demand
- % change in quantity demanded of a good in response to 1% change in income (approximately).
\[e_{Q_d,I} = \frac{percent \ change \ in \ Q_d}{percent \ change \ in \ I} \]
\[ = \frac{\Delta Q_d}{Q_d}/\frac{\Delta I}{I}\]
Normal goods: \(e_{Q,I} > 0\)
Inferior goods: \(e_{Q,I} < 0\)
Luxury goods: \(e_{Q,I} > 1\)
E.g., cocaine is a luxury good, if, when I win £1000 in the lottery, I will increase my consumption of cocaine by more than £1000 … (assuming, as in classical models, that I treat all sources of income the same…
Some real-world discussion of this
Sir, Professor Gordon Gemmill (Letters, December 14), surprisingly for a trained economist, assumes an income elasticity of demand of zero for housing: that is, that people do not demand more and better housing as they become richer. Nowhere in the world is this the case! My own empirical work demonstrates that around two-thirds of the rise in UK house prices, corrected for general inflation, since 1980 is because supply is not keeping up with income and population growth. Other drivers do exist … The price effects of extra supply take time to build up. I agree on that. But just imagine what would happen if we did nothing more than we are now doing: population and income growth would drive prices even higher even though we already hold the record for rises in house prices since 1970 among the group of seven leading high-income countries. We need to build far more housing, in the right locations. And we need to start now. - Prof John Muellbauer Nuffield College, Oxford, UK
- Cross-price elasticity of demand (read about this in one of the suggested texts please)
4.8 More formal statements of properties of Marshallian demand
Source: Preston, 2006; https://www.ucl.ac.uk/~uctp100/g021/g021lect.pdf; notation changed.
Note: bold means ‘vectors’.
Budget set
\[B=\{\mathbf{q} \in R^n_{+}|\mathbf{p'q} \leq I \}\]
Slopes \(dq_i/dq_j|_B = -p_j/p_i\). in Consumer chooses \(\mathbf{x}(\mathbf{p},I)\in B\); Marshallian demands.
The graph of \(x_i(\mathbf{p},I)\) in \(I\) is the ‘Engel curve’. The Engel curve simply depicts how quantity demanded of one good increases in (an individual’s) income, holding all else constant.
Graphing the Engel curve (some links):
Some decent youtube videos on this, in a simple form.
We see the graphical derivation of an Engel curve:
For a neccesity (i.e., a non-luxury) good here
for a normal good (remember, an inferior good is also a neccesity, but not necessarily vice versa) here.
And for a luxury good here (remember, a luxury good is also a normal good, but not necessarily vice versa)
He presents the indifference curves and then ‘Income consumption curve’… the optimizing choice of each of two goods as income increases. Next, he plots this for one good only, yielding the ‘Engel curve’.
Notice how the Engel curve gets steeper for a necessary good, but gets shallower for a luxury good. For an inferior good, it has a negative slope.
Of course the response to changes in income need not be constant throughout the whole range … a good can even be inferior in one range and luxury within another range of income.
See Professor Joon Song’s video HERE for an integrated presentation of the income expansion path, the Engel Curve, and income elasticity.
Total budget (income) elasticity:
\[\eta_i \equiv \frac{\partial x_i}{\partial I} / \frac{x_i}{I} = \frac{\partial ln(x_i)}{\partial ln(I)} \]
‘By what percentage does consumption of \(x_i\) change as income changes by a small percent?’
- \(\eta_i > 0\) \(\rightarrow\) ‘normal good’, otherwise ‘inferior’
Applying this to ‘budget shares’: \(s_i \equiv p_i x_i/I\)… noting these must add up to one: \(\sum_{i=1..n}s_i=1\)
- \(\eta_i > 1\) \(\rightarrow\) ‘luxury’ (budget share rises in income), otherwise ‘neccessity’
Similarly, …
$_i / $
4.9 Adding-up (‘aggregation’) etc
If an individual ‘always spends all her income’ then this equality must hold everywhere. This implies a set of relationships:
between how things change in response to income and price… -as one spends more on one good she must spend less on another
between shares of expenditure and how these change.
Rewriting the budget constraint with the Marshallian demands vector \(\mathbf{x}\), and imposing budget-balance (which can be proved must hold for an optimising consumer given local nonsatiation):
\[\mathbf{p'x}(\mathbf{p},I) = I\]
TODO: I hope to include a video here
Differentiating this wrt \(I\) yields Engel aggregation:
\[\sum_i p_i \frac{\partial x_i}{\partial I} =\sum_i \frac{p_i x_i}{I} \frac{\frac{\partial x_i}{\partial I}}{\frac{x_i}{I}} =\sum_i s_i\eta_i = 1\]
\(\rightarrow\) Sum (over all goods) of ‘budget share’ \(\times\) ‘income elasticity’ must add up to one.
Thus not all goods can be inferior (\(\epsilon_i < 0\)); these must be balanced by normal goods (including some luxuries, to get the average above one.)
Also not all goods can be luxuries (\(\epsilon_i > 1\)) and not all goods can be necessities (\(\epsilon_i < 1\)). These must balance each other out, in an expenditure-weighted sense.
Differentiating the ’demand budget constraint wrt some price \(p_i\) yields Cournot aggregation:
(rem: product rule here, carried through sums )
\[x_j + \sum_i p_i \frac{\partial x_i}{\partial p_j} = 0 \rightarrow\] The marginal change in expenditure as \(j\)’s price changes sums the amount of \(j\) originally purchased and the sum of the prices of other goods times their responses to the price change in j.
Next we multiply this by the price of j and divide by income \(I\) to get (bunch of steps here:)
\[ -s_j = \sum s_i \epsilon_{ij} \]
The budget share on j plus the sum of the budget shares of other goods multiplied by the cross-price elasticities must add up to 0. … as the price of j increases the price-weighted consumption shares must decrease. So, e.g., all goods cannot be Giffen.
4.10 Enrichment, further material to consider
To consider constrained optimization (with many goods) using the Lagrangian method see THIS supplement (based on David Autor’s notes)
The dual ‘minimization problem’ and ‘Hicksian demand’ are discussed HERE. For a simpler treatment, please see QMC Chapter 20.3*.
Recall: QMC refers to ‘Quantum Microeconomics with Calculus’ by Yoram Baumann
Further doctoral-prep concepts
Some examples of things you may need to learn and use for a PhD micro module, (although only a small subset of economists actually use this in their research!). You will not be directly examined on this in the present module. Some of these are covered or touched on in O-R
Another taste, nice UCLA notes here
As noted, standard utility functions are defined up to ‘monotonic transformations’. We can derive proofs of the invariance of the implied preferences to these.
What conditions on a (multivariate) utility function ensure it exhibits the equivalent of a diminishing marginal rates of substitution? - Something called ‘quasi-concavity’, equivalent to ‘having convex upper contour sets’
Representation of the MRS between all goods as a matrix, depicting the properties of this
- Strict quasi-concavity takes the place of DMRS in ensuring ‘simple optimisation conditions’
Several topics that we have skipped
Formal definitions of Hicksian (compensated) demand functions
Substitution and income effects
Deriving and using the Slutsky decomposition relating Marshallian and Hicksian demand, - a set of other exact relationships between functions that come out of the consumer’s minimisation and equivalent maximisation problem
Some of these concepts are important for characterizing the welfare effects of price changes and policy changes (including taxation), and for conceptualizing issues involving multiple constraints on consumer optimization (e.g., rationing). I will provide notes on these for anyone who is interested.
- Aggregation of individual demand functions into ‘market demand’, and the properties of this
References
Reinstein, David. 2014. “The Economics of the Gift.”
Society, The Econometric. 2014. “Observing Violations of Transitivity by Experimental Methods Author ( S ): Graham Loomes , Chris Starmer and Robert Sugden” 59 (2): 425–39.
Waldfogel, Joel. 1993. “The Deadweight Loss of Christmas.” The American Economic Review 83 (5): 1328–36.
Image source: SilverStar at English Wikipedia, CC BY-SA 3.0 http://creativecommons.org/licenses/by-sa/3.0/, via Wikimedia Commons↩︎
Source: https://en.wikipedia.org/wiki/Revealed_preference#/media/File:Weak_Axiom_of_Revealed_Preferences.png↩︎
{kind=link}