19 Bayesian approaches
19.1 My (David Reinstein’s) uses for Bayesian approaches (brainstorm)
19.1.1 Meta-analysis of previous evidence
Of prior work, especially on motivators of (effective) charitable giving and responses to effectiveness information
Of my own series’ of experiments (potentially joint with prior work)
19.1.2 Inference, particularly about ‘null effects’
When/what can we say about the ‘absence of an effect’
How to integrate into inferences from diagnostic testing (e.g., common-trend assumption)?
19.1.3 ‘Policy’ and business implications and recommendations
In particular, in a charitable giving social-media fundraising context, we might consider whether it is worth offering ‘seed contributions’ to encourage giving on existing pages. If so, ‘which pages should we seed and how much?’
19.1.4 Theory-driven inference about optimizing agents, esp. in strategic settings
- Especially in the context od ‘predicted contributions to public goods… and 2nd order beliefs’
19.1.5 Experimental design
Optimal treatment assignment, with previous observables and a track record
Sequential designs
Bayesian Power calculation
#sessionInfo()Package loadings from Kurtz:
pacman::p_unload(pacman::p_loaded(), character.only = TRUE)
ggplot2::theme_set(ggplot2::theme_grey())
bayesplot::color_scheme_set("blue")
library(tidyverse) #adds in next chapter19.2 ‘Statistical thinking’ (McElreath) and AJ Kurtz ‘recoded’ (bookdown): highlights and notes
McElreath’s course and text looks great. I’m taking selective notes here; I’ll try to incorporate content from both text and youtube video lectures.
AJ Kurtz has re-written the code using the brms package, which he finds superior. More crucially for me, he redoes the code using ggplot and tidyverse?
I’ve also forked Kurtz’s repo here, which I may play with.
19.2.1 1. The Golem of Prague (map ant the territory)
Don’t let your model or approach turn into a Golem you can’t control. Don’t ‘believe the model’; continuously validate it. The map is not the territory.
‘Statistical decision trees’ lend a false sense of security… and almost never fit the actual case we are dealing with. (fig 1.1)
Statistical models are non-unique maps to ‘process models’ which are non-unique maps to hypotheses. (He offers the example of neutral evolutionary selection’ example.)
This makes strict falsification impossible: How can you falsify a hypothesis/theory if it corresponds to a wide set of process models and statistical models, many of which overlap other hypotheses?
But this warning is at least as relevant for Bayesian analyses, which must be based on specifically defined (term) models of the DGP etc. Thus he recommends caution and continuous (?) interplay between the model and the data. (See next chapter … ‘small worlds and large worlds.’)
He also suggests we refer not to ‘Confidence intervals’ or even ‘Credible intervals,’ but to ‘Consistent intervals’ … as in ‘these intervals are consistent with the model and data.’
And…
[so you should] ‘…Explicitly compare predictions of more than one model’
Rethinking: Is NHST falsificationist?

(#fig:failure_of_falsification.png)From McElreath video lecture 1
Null hypothesis significance testing, NHST, is often identified with the falsificationist, or Popperian, philosophy of science. However, usually NHST is used to falsify a null hypothesis, not the actual research hypothesis. So the falsification is being done to something other than the explanatory model. This seems the reverse from Karl Popper’s philosophy.
I.e., scientists have turned things upside down; originally the idea was that you had substitute of hypotheses that you would want to falsify and now we try to falsify silly null hypotheses that “nothing is going on.” You should try to really build a hypothesis and test it not just reject that nothing is going on.
19.2.1.1 Book’s foci
- Bayesian data analysis
- Multilevel modeling
- Model comparison using information criteria
19.2.2 2. Small Worlds and Large Worlds
… The way that Bayesian models learn from evidence is arguably optimal in the small world. When their assumptions approximate reality, they also perform well in the large world. But large world performance has to be demonstrated rather than logically deduced. (p. 20)
We imagine a bag filled with four marbles, each of which is blue or white.
“So, if we’re willing to code the marbles as 0 =”white" 1 = “blue,” we can arrange the possibility data in a tibble as follows." I.e., we can consider the five possible worlds, in each of which the bag has a different number of white and blue marbles, and represent each of these worlds as a column vector:
d <-
tibble(p_1 = 0,
p_2 = rep(1:0, times = c(1, 3)),
p_3 = rep(1:0, times = c(2, 2)),
p_4 = rep(1:0, times = c(3, 1)),
p_5 = 1)
d## # A tibble: 4 x 5
## p_1 p_2 p_3 p_4 p_5
## <dbl> <int> <int> <int> <dbl>
## 1 0 1 1 1 1
## 2 0 0 1 1 1
## 3 0 0 0 1 1
## 4 0 0 0 0 1
We visualize this in the plot below, where each column is one ‘world’:
d %>%
gather() %>% #make it long, with an ket variable for the possibility 'world'
mutate(x = rep(1:4, times = 5), #an index for 'which ball'
possibility = rep(1:5, each = 4)) %>% #distributing the 'which world' index
ggplot(aes(x = x, y = possibility,
fill = value %>% as.character())) +
geom_point(shape = 21, size = 5) +
scale_fill_manual(values = c("white", "navy")) +
scale_x_continuous(NULL, breaks = NULL) +
coord_cartesian(xlim = c(.75, 4.25),
ylim = c(.75, 5.25)) +
theme(legend.position = "none")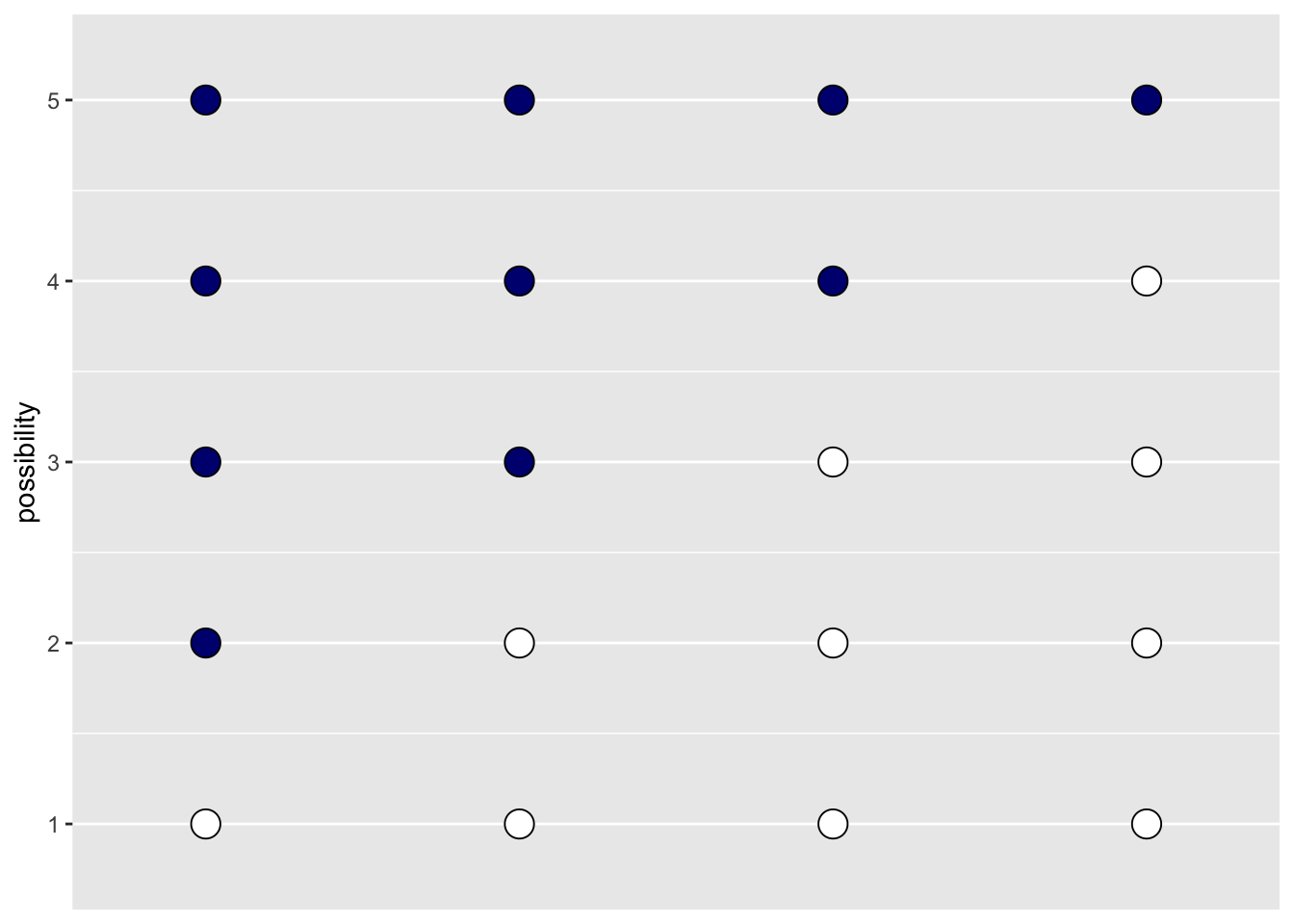
Simple combinatorics (permutations rule) tells us how many ‘ways’ we can draw 1, 2, and 3 marbles… Here we think about ‘which’ marble is drawn, and not just ‘which color’ it is. We can draw marble 1-4, the first time, then 1-4 the second time, and then 1-4 the third time… so possibilities=marbles ^ draw.
tibble(draw = 1:3,
marbles = 4) %>%
mutate(possibilities = marbles ^ draw) %>%
knitr::kable()| draw | marbles | possibilities |
|---|---|---|
| 1 | 4 | 4 |
| 2 | 4 | 16 |
| 3 | 4 | 64 |
Next, there is a huge amount of code explaining how to make the ‘garden of forking paths’ diagrams. I’m basically going to skip all that code, and paste in a few images. You can find all the code HERE
Suppose there is only one blue ball and three white balls, possibility ‘2’ above. For this world, we see the full ‘garden of forking paths’ — the number of ways to select 1, 2, and 3 balls (with replacement) — below.
Every path starting from the center is a possible (sequence of) draws.
[CUT A BUNCH HERE]
19.3 Title: “Introduction to Bayesian analysis in R and Stata - Katz, Qstep”
Content from notes from this lecture
19.3.1 Why and when use Bayesian (MCMC) methods?
19.3.1.1 Pros
No need for asymptotics … good when sample sizes are small
Incorporate previous information
You can consider the ‘robustness to other priors’
Fit complex nonstandard models … e.g., with difficult functional forms or likelihood settings (more computation, less thinking)
Easy to make predictions (e.g., simulate scenarios) after estimation
Incorporate evidence, results, expert judgement
(‘restrictions’ with some lee-way?)
(ISn’t this the same as number 2?)
- Cleaner treatment/imputation of missing values … these are just parameters
19.3.1.2 Cons
Must specify prior distributions … allows subjective judgement
Different way of thinking about stats and inference; probability distributions and simulations, not much about p-values, point estimates and standard errors … path dependence
Computational cost
This is an R Markdown document. Markdown is a simple formatting syntax for authoring HTML, PDF, and MS Word documents. For more details on using R Markdown see http://rmarkdown.rstudio.com.
When you click the Knit button a document will be generated that includes both content as well as the output of any embedded R code chunks within the document. You can embed an R code chunk like this:
19.3.1.3 Why more popular today?
- Starting from around 2005 in Political Science and Sociology
Computational revolution comes from Markov chain Monte Carlo (MCMC) methods … don’t need analytical solutions
Software implementations – many in R, specialised software like EWinBugs, JAGS, STAN; also increasingly in Stata
19.3.2 Theory
Bayes theorem … inverting conditional probability thing … ‘inversion’ to make inferences about the parameters
- In Bayesian stats the parameters (and sometimes missing values) are random variables, we make probability statements about them
\[P(A|B)=P(B|A)P(A)/P(B)\]
Frequentist: Point estimates, unknown fixed parameters, data from a hyol repeataable random sample
Bayesian: Fixed data (from the experiment), parameters are random variables … results based on probability distributions about rthese
Classical statistics: likelihood of data given parameter: \(p(y|\theta)\)
Bayes we want, \(p(\theta|y) = p(y|\theta)p(\theta)/p(y)\)
\(p(y)\) is a ‘constant’ in our estimation … the data is fixed.
So it’s proportional to \(p(\theta|y) = p(y|\theta)\times p(\theta)\)
\(p(y|\theta)\) is what we max when we do ML
$ p()$: prior distribution capturing beliefs about \(\theta\)
19.3.2.1 So how do we estimate it?
Specify a probability model, a distribution for Y (likelihood function) and the priors for \(\theta\)
Solve (find) the posterior distribution \(p(\theta|Y)\) and summarise the parameters of interest
In practice, step 2 is usually done via MCMC simulation rather than analytically.
… via simulations, I approach the ‘true’ value on \(\theta\)
(Given ‘regularity conditions’)
19.3.2.2 Linear regression model example
\[Y = x'\beta+\epsilon\] with n obs
only random term is epsilon … natural candidate is a normal distribution, so \(Y \sim N(x'\beta,\sigma^2_e)\)
So we want to find \(p(\beta, \sigma^2_\epsilon|Y,X)\). This depends on the choices of \(p(\beta)\) and \(p(\epsilon)\). Could choose conjugate priors, leading to a particular joint posterior, you can solve it analytically.
Can yield a joint posterior.
Instead, let’s assume that the latter (variance) parameter is known, you can show that the posterior for \(\beta\) is also normally distributed. (Conjugate)
Similarly, if we assume \(\beta\) is known, if the variance term had an inverse gamma distribution (prior), so will the posterior.
In these conjugate priors, the posterior mean will be a weighted average of the priors and the data.
19.3.2.3 Gibbs
Needs closed form conditional posterior for every parameter.
What Gibbs sampler does is break the parameter space into sets of parameters
Choose starting values, \(\theta^0_1,...\theta^0_k\)
sample from the first parameter’s distribution given the others … the second one, … the k’th one .
Repeat step 2 … thousands of times (starting with the parameters from the previous iteration) Eventually ‘we obtain samples of \(p(\theta|y)\)’
But if we don’t have a closed form, we cannot simply sample from known distributions in each step
E.g., in case of Logit distribution.
19.3.2.4 Metropolis Hastings
- Choose ‘proposal distribution’ to sample parameter values (a candidate like normal, uniform)
- Start w a prelim guess for parameter values \(\theta_0\)
- At iteration t sample a proposal \(\theta_t\) from \(p(\theta_t|\theta_{t-1})\) ?? what does this come from?
- If \(p(\theta_t|y)>p(\theta_{t-1}|y)\) accept it as the new value of \(\theta\). ??? how is this computed if we don’t have conjugate closed-form posteriors?
- Otherwise flip a coin with probability r = (ratio of those probabilities)
- if coin tosses heads, accept as new theta, otherwise stay at previous theta
- allows algorithm to avoid getting stuck at local maxima
Commonly used proposal: random walk sample: \(\theta_t=\theta_{t-1}+z_t\), \(z_t \sim f\)
?? I do this because there is no analytical way to derive this, unlike in the conjugate case, where we might use the Gibbs
- can combine Gibbs with Metropolis steps; relevant to some problems
19.3.2.5 Assessing convergence
previous … ‘eyeballing’
formal:
- single-chain tests (Geweke/Heidel) … is the last part of the chain stable (stationary)… compare simulation at middle and end, is there much variation?
- multiple-chain test… (starting from different values), do they end similar … Gelman-Rubin diagnosting \(\hat{R}\)
- typically either a very long chain and use GH convergence, or multiple shorter chains and use \(\hat{R}\)
Gabriel: Gelman-Rubin is probably preferred; more conservative
?? What am I iterating towards? Converging on what?
19.3.2.6 Assesing ‘fit’ in Bayesian
- No r-squared
- Typical measure is ‘posterior predictive comparisons’
\(p(y_{replicated}|y_{observed}= ...\)
- Simulate data from estimated parameters
- Compare to observed data
- Use an overall fit measure to assess model fit
E.g., percent correct predictions (binary), whether the true data is within the 95% CI of the replicates, deviance
For each replicate Choose statistic D, compare the replicated
\(D(y^s_{replicated})\) against \(D(y^s_{observed})\)
Quantify the discrepancy … percent of correct predictions, proportion of times replicated y is below true y … compute ‘bayesian p-value’s’
Systematic differences between replicate and actual data indicate model limitations
(?? what are reasonable values here??)
19.3.3 Comparing models … Equivalent of ‘likelihood’
‘Deviance Information Criterion’ (most used); specific for MCMC simulations: compares expected LL of the model (of the data given the estimated parameters; average here across much of the later points in the chain) against the llhd at the posterior parameter mean. Always select model with lowest DIC.
Bayes Factor (less used): Ratio of llhd of the models; higher BF means model is more supported; BF>10 seen to provide strong evidence for model w higher value
19.3.4 On choosing priors
Most social scientists use non-informative or vague priors; i.e., large variance… e.g., \(\beta \sim N(0,1000)\)
But its often useful to incorporate information into your priors
Small pilot to test, \(\rightarrow\) data \(Y_1\), another study gives data \(Y_2\); repeated application of Bayes theorem gives the posterior.
Same result whether you obtained these together, or whether you did one and then updated (e.g., via an MCMC, starting with the first one as a prior)
Conjugate priors (mentioned before)
- Jeffrey’s priors (??)
19.3.5 Implementation
If you don’t need to do fancy things, and don’t want to (?) generate the full posterior distribution (or something)
Some Stata/R commands that make Bayesian look frequentist.
In Jags and Winbugs, we only have to specify the prior… rest is done for us
Jags is great … you only need to do self-coding with lots of data and super complicated models as it can freeze up
We went through it the fancy way in Probit.R
Then the easy way with ‘script probit Jags.R’
19.3.6 Generate predictions from a WinBUGS model
You can just generate these outcomes …
Prediction: generate a new observation #note, he is doing one per iteration, but since these are convergent it would be basically the same if you just chose a random iteration and did all the draws from that one
19.3.7 Missing data case
One solution – multiple imputation
- choose imputation model to predict missings,
- generate many copies of orig data set, imputing missibg value for each
- 2 more steps here
Need a model for X|alpha, because missing variables are random variables
19.3.8 Stata
Has some rather simple implementations; e.g., just using commands like bayes: regress y x
19.3.9 R mcmc pac
Also simple code; great for standard use
Speedup with parallelization; see “script for parallel probit.R” and “parallelprobit.R”
More advanced: C++; can integrate it with Rcpp, or even use Exeter’s ISCA cluster
summary(cars)## speed dist
## Min. : 4.0 Min. : 2
## 1st Qu.:12.0 1st Qu.: 26
## Median :15.0 Median : 36
## Mean :15.4 Mean : 43
## 3rd Qu.:19.0 3rd Qu.: 56
## Max. :25.0 Max. :12019.4 Other resources and notes to integrate
Hey stats twitter: got a very sharp psych UG student wanting to dive into Bayes. Many resources are too technical (i.e., not good teaching texts for UG level, but useful references). Where should I point her?
— Tom Carpenter (@tcarpenter216) February 1, 2020